
深入Redis系列(七)Redis事务原理详解

这篇文章,我想说说redis的事务,看完这篇文章也许你可以掌握以下知识或者加深对它们的印象和理解:
_ Redis事务的使用; _
_ Redis事务的原理; _
_ 乐观锁和悲观锁; _
_ Redis事务是否满足ACID; _
pipeline和Redis事务比对;
_ Redis与关系型数据库事务的异同; _
_
**
** _
在开始正文内容之前,想让大家思考几个问题,并带着这几个问题往下阅读,假如面试官问到了这几个问题大家会如何应对?
-
Redis事务是否满足以及在什么场景才满足原子性、一致性、隔离性和持久性;
-
Redis事务为什么不支持回滚操作;
-
Redis事务为什么不使用锁机制,为什么使用悲观锁,为什么乐观锁不是锁,什么情况下你才会需要使用锁;
-
如果让你设计一个乐观锁,你会如何实现;
-
Redis事务和Pipeline都会暂存多条命令并一次性执行,它们有什么区别;
下面正式开始我们的Redis事务详解,让我们对事务产生更深的理解。
对于事务我们并不陌生,事务本质是一组命令的集合,支持一次执行多个命令,一个事务中所有命令都会被序列化。在redis事务的执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
总结来说,redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
下面先介绍Redis事务涉及到的命令,然后再对每一条命令介绍Redis事务实现的原理。
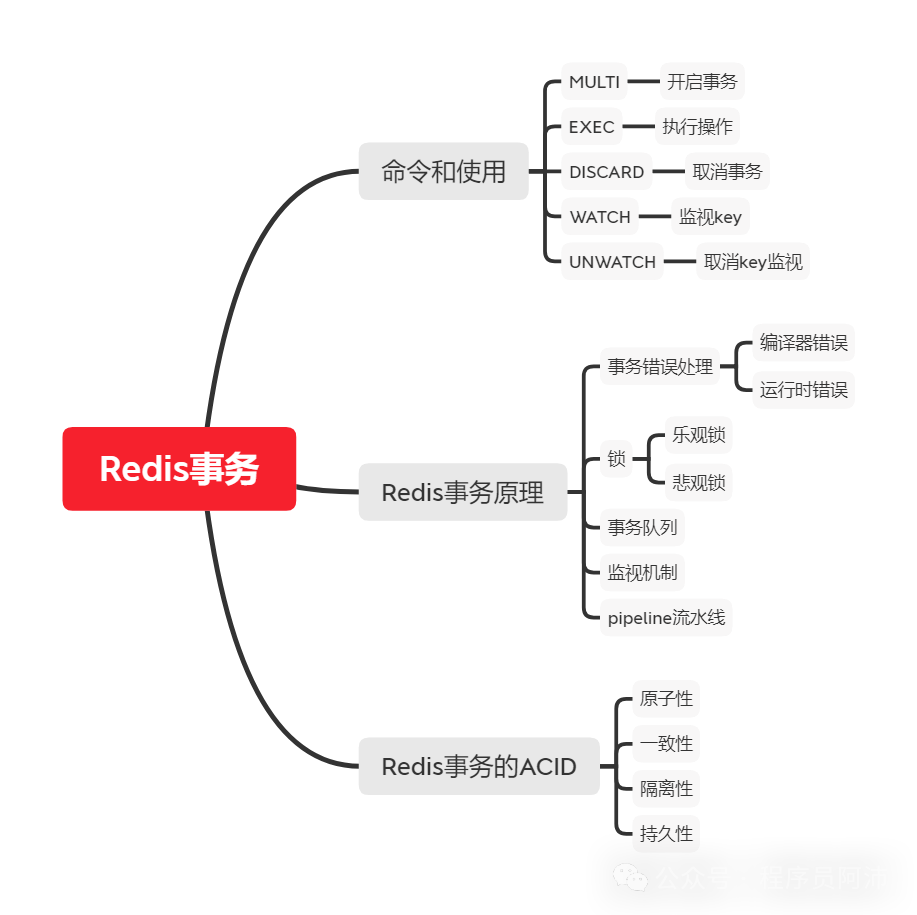
一、Redis事务如何使用
以下是Redis事务的相关命令:
MULTI :开启事务,redis会将后续的命令逐个放入队列中,然后使用EXEC命令来原子化执行这个命令系列。
EXEC:执行事务中的所有操作命令。
DISCARD:取消事务,放弃执行事务块中的所有命令。
WATCH:监视一个或多个key,如果事务在执行前,这个key(或多个key)被其他命令修改,则事务被中断,不会执行事务中的任何命令。
UNWATCH:取消WATCH对所有key的监视。
一个redis事务的标准执行如下所示:
1. 执行一个redis事务
127.0.0.1:6379> set k1 v1OK
127.0.0.1:6379> set k2 v2OK
127.0.0.1:6379> MULTIOK
127.0.0.1:6379> set k1 11QUEUED
127.0.0.1:6379> set k2 22QUEUED
127.0.0.1:6379> EXEC1) OK2) OK
127.0.0.1:6379> get k1"11"
127.0.0.1:6379> get k2"22"
2. 取消一个redis事务
127.0.0.1:6379> MULTIOK
127.0.0.1:6379> set k1 33QUEUED
127.0.0.1:6379> set k2 34QUEUED
127.0.0.1:6379> DISCARDOK
二、Redis事务是怎么实现的(Redis事务原理)
一个事务从开始到结束通常会经历以下三个阶段。
事务开始
命令入队
事务执行
1. 事务开始
MULTI命令的执行标志着事务的开始。
MULTI命令可以将执行该命令的客户端从非事务状态切换至事务状态,这一切换是通过在客户端状态的flags属性中打开REDIS_MULTI标识来完成的。
2. 命令入队
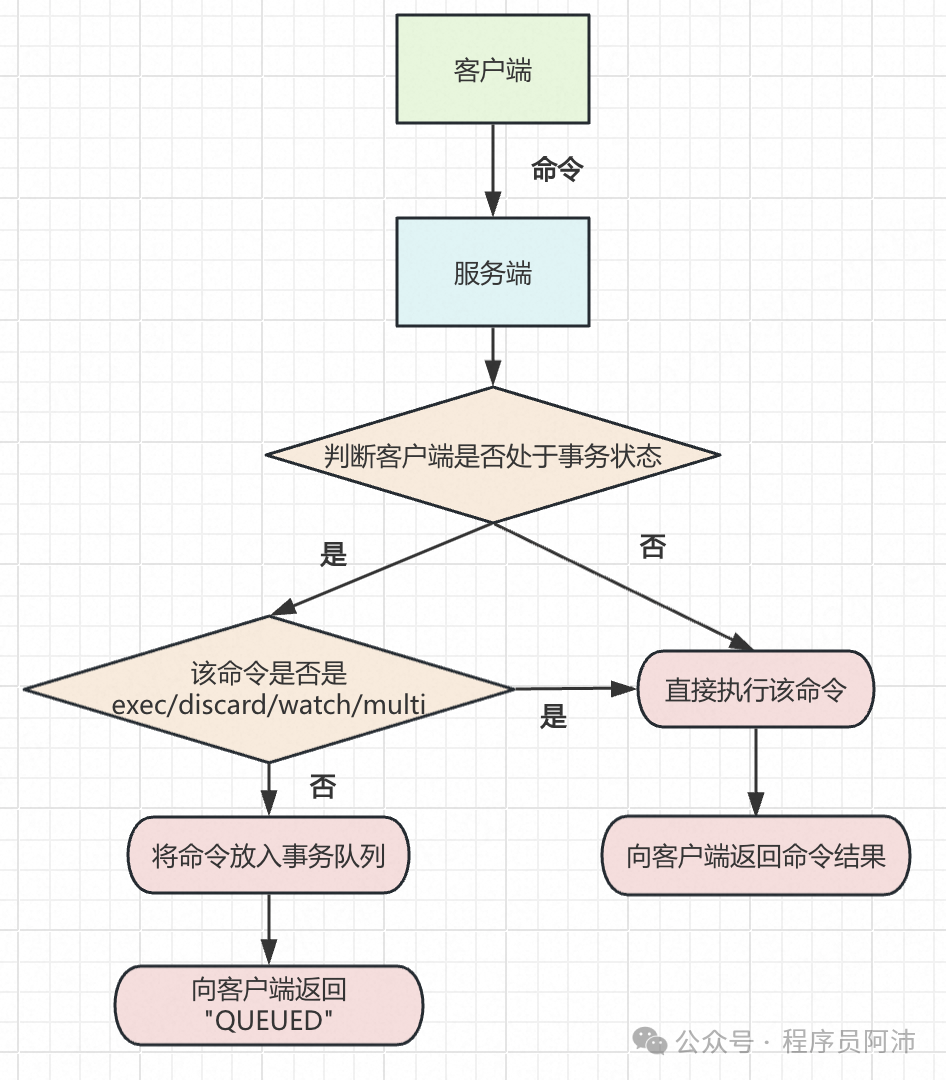
当一个客户端切换到事务状态之后,服务器会根据这个客户端发来的不同命令执行不同的操作。
如果客户端发送的命令为 EXEC、DISCARD、WATCH、MULTI四个命令的其中一个,那么服务器立即执行这个命令。
与此相反,如果客户端发送的命令是EXEC、DISCARD、WATCH、MULTI四个命令以外的其他命令,那么服务器并不立即执行这个命令,而是将这个命令放入一个事务队列里面,然后向客户端返回
QUEUED 回复。
服务器判断命令是该入队还是该立即执行的过程可以用流程图来描述。
3. 事务队列
每个Redis客户端都有自己的事务状态,这个事务状态由一个multiState结构表示。事务状态包含一个事务队列以及一个已入队命令的计数器,这个事务队列由multiCmd数组表示,而计数器也可以说其实是事务队列的长度。
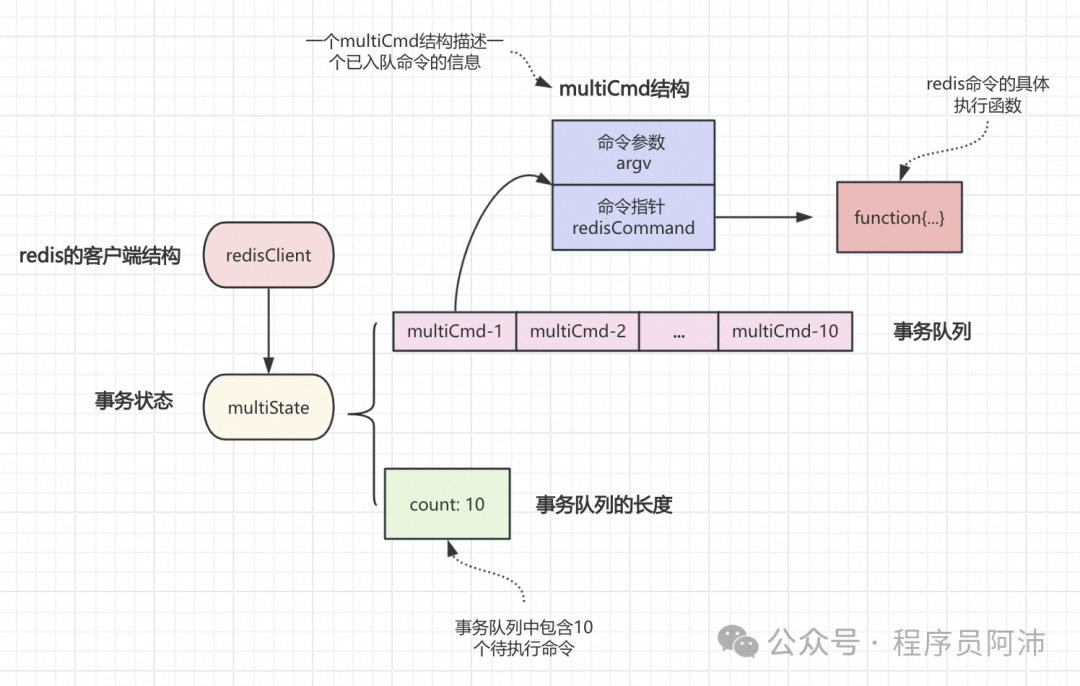
事务队列结构如下,它是一个数组,数组中的每个multiCmd结构都保存了一个已入队命令的信息,包括指向命令实现函数的指针、命令的参数,以及参数的数量。
4.执行事务
当一个客户端向服务器发送EXEC命令时,这个EXEC命令将立即被服务器执行。服务器会遍历这个客户端的事务队列,执行队列中保存的所有命令,最后将执行命令所得的结果全部返回给客户端。
三、Redis事务出现错误是否会导致命令回滚?
redis在面对事务中发生的错误时会有区别的判定 命令是否能执行成功的。
1.语法错误(编译器错误)
已知k1和k2这两个key对应的值分别是v1 和 v2。
在开启事务后,修改k1值为11,k2值为22,但k2语法错误,此时会导致事务提交失败,k1、k2保留原值。
127.0.0.1:6379> MULTIOK
127.0.0.1:6379> set k1 11QUEUED
127.0.0.1:6379> sets k2 22(error) ERR unknown command `sets`, with args beginning with: `k2`, `22`,
127.0.0.1:6379> exec(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k1"v1"
127.0.0.1:6379> get k2"v2"
2.Redis类型错误(运行时错误)
在开启事务后,修改k1值为11,k2值为22,但将k2的类型作为List来使用lpush命令操作,此时在运行时redis会检测到类型错误,最终导致事务提交失败,此时事务并没有回滚(因为redis事务没有回滚的概念),而是跳过错误命令继续执行,结果k1值改变、k2保留原值。
127.0.0.1:6379> MULTIOK
127.0.0.1:6379> set k1 11QUEUED
127.0.0.1:6379> lpush k2 22QUEUED
127.0.0.1:6379> EXEC1) OK2) (error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379> get k1"11"
127.0.0.1:6379> get k2"v2"
之所以发生这种差异是因为编译错误可以在真正执行命令之前就能检测到,此时redis还没有开始执行事务队列中的命令,因此redis可以放弃执行事务队列中的所有命令。
运行时错误是当redis执行某条命令才能检测出来,但此前已执行的事务中的命令已经执行完毕。Redis实际上没有回滚功能,discard命令只能取消事务,不能回滚。因此事务队列已执行的命令会真实生效。
为什么 Redis 不支持回滚?
如果你有使用关系式数据库的经验, 那么 “ Redis 在事务失败时不进行回滚,而是继续执行余下的命令 ”这种做法可能会让你觉得有点奇怪 。
以下是这种做法的优点:
a.Redis命令只会因为错误的语法而失败,或是命令用在了错误类型的键上面。
这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中 。
因为不需要对回滚进行支持,这样 Redis 的内部也可以保持简单且快速。
b.有观点认为 Redis 处理事务的做法会产生 bug , 然而在通常情况下, 回滚并不能解决编程错误带来的问题。例如 如果你本来想通过 INCR
命令将键的值加上 1 , 却不小心加上了 2 , 又或者对错误类型的键执行了 INCR , 回滚是没有办法处理这些情况的。
四、Redis事务有使用到锁吗
先告诉大家答案, Redis事务需要用到watch命令和乐观锁来保证隔离性和一致性,但其实也可以说Redis事务中也
并没有使用锁,因为乐观锁本质上不是一把锁,而是一种监听和检验数据是否被修改的机制。
在讨论这个问题之前,我们不妨想想看,为什么需要用到锁,什么时候才需要用到锁?
使用锁是为了避免多个线程或者客户端并发修改数据导致的数据混乱问题,通过对数据加锁使得多个并发的线程或客户端在修改这个数据时是串行发生的,从而保证并发场景下的数据一致性。
像MySQL这种关联数据库在事务中修改数据时就是通过对数据上锁来实现事务在多个客户端之间的隔离性和一致性的。
1. Redis事务如何实现隔离性和一致性?
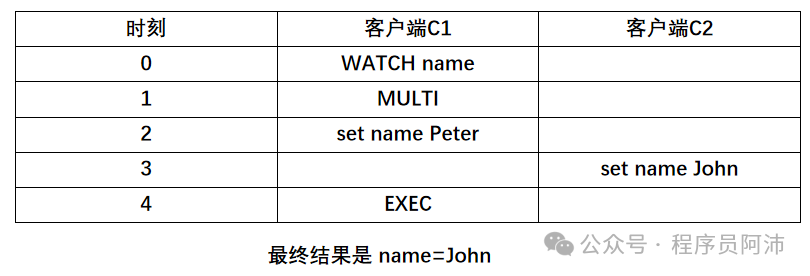
不妨看个Redis客户端并发修改数据的例子。客户端C1开启一个事务T1并在这个事务
中修改name这个key的值为peter,之后客户端C2不开启事务直接修改name的值为john,然后C1才执行EXEC提交事务。
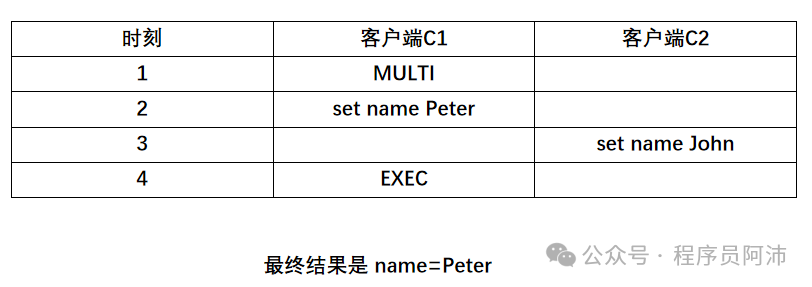
按照事务的一致性,因为客户端C2修改name在C1修改name之后发生,所以正确的数据状态应该是 name=john,但实际结果却是 name=Peter。
Question 1:为什么 实际结果是 name=Peter?
首先,Redis事务不会自动为被修改的数据上锁。
正因为C1在修改数据name时没有上锁,因此 C2 执行set操作可以成功。而与此同时,C1
的set命令还暂存在事务队列中没有执行,此时name=John。当C1执行了EXEC后,C1才执行成功 set name
Peter,从而将name的值覆盖为Peter。
name没有达到我们“常理”中希望的name=John的预期。 所以此时Redis的事务是没有达到一致性的。
C1在事务中修改name的时候,C2理应无法修改name,但是C2却能够修改name成功。 所以此时Redis的事务也是没有达到隔离性的。
Question 2:如何才能让Redis的事务达成隔离性和一致性?
让事务达成隔离性和一致性本质是如何解决并发场景下修改数据时的脏写问题,或者说并发场景下的数据安全问题。
通常来说,可以通过悲观锁和乐观锁两种方式来保证并发场景下数据的安全。
悲观锁的保证方式
是客户端C1在修改name这个数据的时候,对name这个key上一把互斥锁或者读写锁,这将导致如果客户端C2也想修改name,就需要等待锁释放。此时客户端C2会处于休眠和阻塞的状态。
乐观锁的保证方式
是客户端C1在修改name之前先监听name,在执行EXEC时,如果检测到C2改变了name,那么C1的事务里所有命令都会被取消。C1如果还想修改name,就需要重试。
上面这两种方式都能保证数据修改是串行的,因此满足隔离性。只不过悲观锁的串行顺序是
先执行C1后执行C2,而乐观锁的串行顺序是先执行C2后执行C1(C1要重试才能执行成功)。
Redis 追求 极致的速 度 , 不希望 让客户端被阻塞,也不希望产生 不必要的锁开销 , 因此采用了无锁的 乐观锁 。
为了更好的让大家理解悲观锁和乐观锁,我想说说 悲观锁为什么叫做悲观锁 & 乐观锁为什么叫乐观锁。
_ 悲观是人类的一种消极情绪,
对应到锁的悲观情绪,悲观锁认为被它保护的数据是极其不安全的,每时每刻都有可能变动,因此具有强烈的独占和排他特性,被悲观锁锁定的数据无法被其他客户端或者线程修改。
_
_
_
_ 乐观锁相反,它总是认为它每次去修改数据的时候其他人不会修改,所以不会对数据上锁,但是在更新的时候会判断一下在此期间 _ 其他人 _
有没有去更新这个数据。 _
从效率上来看,乐观锁适用于多读少写的场景,而悲观锁适用于少读多写的场景。
如果乐观锁用于多写少读场景的话,会频繁重试导致性能降低;
如果悲 观锁 用于多读少写 场 景的话,会在大多数本不必要加锁的时候都加锁,而加锁本身也是一种开销 ;
2. Redis乐观锁是怎么实现的
Redis的乐观锁是通过一种叫做 哈希链表的数据结构 和WATCH命令 来实现的。
WATCH命令可以在EXEC命令执行之前,监视任意数量的数据库键,并在EXEC命令执行时,检查被监视的键是否至少有一个已经被其他客户端修改过了。如果是的话,服务器将拒绝执行事务,并向客户端返回代表事务执行失败的空回复。
例如:
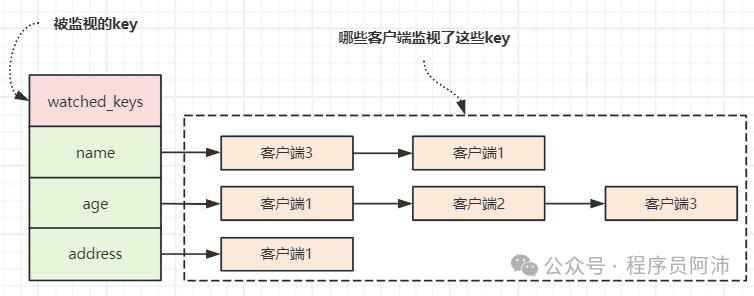
a. 被监视key的存储
每个Redis数据库都保存着一个watched_keys字典,这个字典的下标是被WATCH命令监视的key,值则是一个链表,链表中记录了所有监视了这个key的客户端。
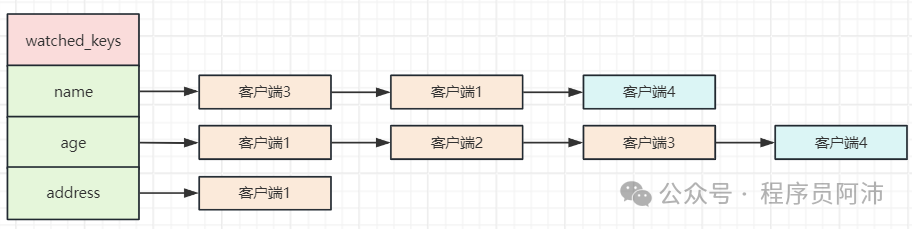
当有一个新的客户端4 执行 WATCH 命令监听 name 和 age时 ,客户端4也会被加入到name和age对应的链表的末尾。
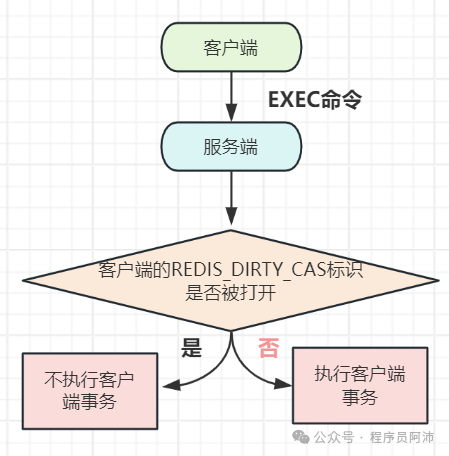
b. 监视机制的触发
所有对任意key修改的命令都会引发Redis对watched_keys字典进行检查,查看是否有客户端监视刚刚被命令修改过的key。
如果有的话,那么Redis会将监视该key的客户端的flags的REDIS_DIRTY_CAS标识打开,表示该客户端的事务安全性已经被破坏。
如此一来,当客户端执行EXEC时,如果该客户端的REDIS_DIRTY_CAS标识是打开状态,那么Redis会拒绝执行该客户端事务队列中的所有命令。
UNWATCH命令可以取消对key的监听。
五、Redis事务是否满足ACID?
1. Redis事务是否满足原子性
如果事务正常执行,没有发生任何错误,那么MULTI 和 EXEC 配合使用,就可以保证多个操作都完成。 但是,如果事务执行发生错误了,原子性还能保证吗?
我们需要分三种情况来看:
a.命令存在语法错误(编译错误);
b.命令存在key的类型和操作不匹配的错误(运行时错误);
c.Redis实例故障导致事务失败;
第一种 情况是, 在执行 EXEC 命令前,客户端发送的操作命令存在语法错误 (比如使用了不存在的命令),在命令入队时就被 Redis
实例判断出来了。 对于这种情况,在命令入队时,Redis 就会报错并且记录下这个错误。
等到执行了 EXEC 命令之后,Redis 就会拒绝执行所有提交的命令操作,返回事务失败的结果。
这样一来,事务中的所有命令都不会再被执行了,保证了原子性。
第二种 情况 是, 命令和操作的数据类型不匹配 ,但 Redis 实例不执行这些命令就不会检查出错误。在执行完 EXEC 命令以后,Redis
实际执行这些事务操作时,就会报错。
虽然 Redis 会对错误命令报错,但还是会把正确的命令执行完。在这种情况下,事务的 原子性就无法得到保证了 。
第三种情况是, 在执行事务的 EXEC 命令时,Redis 实例发生了故障导致事务执行失败 。
在这种情况下,如果 Redis 开启了 AOF 日志,那么只会有部分的事务操作被记录到 AOF 日志中。 我们需要使用 redis-check-aof
工具检查 AOF 日志文件,这个工具可以把未完成的事务操作从 AOF 文件中去除。
这样一来,我们使用 AOF 恢复实例后,客户端被中断事务的所有命令操作不会再被执行,从而保证了原子性。
如果 AOF 日 志并没有开启,那么实例重启后,数据也都没法恢复了,此时也就谈不上原子性了。
简单小结下:
命令语法错误,会放弃事务执行,保证原子性;
命令实际执行时报错,不保证原子性;
EXEC命令执行时实例故障,如果开启了 AOF 日志,可以保证原子性;
2. Redis事务是否满足一致性
事务的一致性保证会受到错误命令、实例故障的影响。所以我们还是按照命令出错和实例故障的发生时机,分成三种情况来看。
情况一: 命令语法错误
在这种情况下,事务本身就会被放弃执行,所以可以保证数据库的一致性。
情况二:命令执行时报错
在这种情况下,有错误的命令不会被执行,正确的命令可以正常执行, 能够保证数据库的一致性,但是会破坏业务的一致性 。
情况三:EXEC 命令执行时实例发生故障
在这种情况下,实例故障后会进行重启,这就和数据恢复的方式有关了,我们要根据实例是否开启了 RDB 或 AOF 来分情况讨论下。
如果我们没有开启 RDB 或 AOF ,那么实例故障重启后,数据都没有了,数据库是一致的。
如果我们使用了 RDB 快照 ,因为 RDB 快照不会在事务执行时执行,所以,事务命令操作的结果不会被保存到 RDB 快照中,使用 RDB
快照进行恢复时,数据库里的数据也是一致的。
如果我们使用了 AOF 日志 ,而事务操作还没有被记录到 AOF 日志时,实例就发生了故障,那么,使用 AOF 日志恢复的数据库数据是一致的。
如果只有部分操作被记录到了 AOF 日志 ,我们可以使用 redis-check-aof 清除事务中已经完成的操作,数据库恢复后也是一致的。
所以,总结来说,在命令执行错误或 Redis 发生故障的情况下,Redis 事务机制对一致性属性是有保证的。
3 . Redis事务是否满足隔离性
事务的隔离性保证会受到和事务一起执行的并发操作的影响。需要就 客户端的 并发操作在EXEC命令执行前发生还是在EXEC命令执行后发生来分析。
a. 客户端的并发操作在 EXEC 命令前执行,此时隔离性的保证要使用 WATCH
机制来实现,否则隔离性无法保证。如果使用了WATCH命令,则可以保证隔离性;
b. 客户端的 并发操作在 EXEC 命令后执行,虽然客户端发起命令请求是并发的,但服务端执行命令是串行的,所以此 时隔离性可以保证。
4 . Redis事务是否满足隔离性
因为 Redis 是内存数据库,所以,数据是否持久化保存完全取决于 Redis 的持久化配置模式。
如果 Redis 没有使用 RDB 或 AOF,那么事务的持久化属性肯定得不到保证。
如果 Redis 使用了 RDB 模式,那么,在一个事务执行后,而下一次的 RDB
快照还未执行前,如果发生了实例宕机,这种情况下,事务修改的数据也是不能保证持久化的。
如果 Redis 采用了 AOF 模式,因为 AOF 模式的三种配置选项 no、everysec 和 always
都会存在数据丢失的情况。所以,事务的持久性属性也还是得不到保证。
所以,不管 Redis 采用什么持久化模式,事务的持久性属性是得不到保证的。
不过,因为 Redis 本身是内存数据库,持久性并不是一个必须的属性,我们更加关注的还是原子性、一致性和隔离性这三个属性。
六、Redis事务和Pipeline很相似,两者有什么区别呢?
如果你还不了解Redis的Pipeline流水线功能,那么我有必要介绍一下它的使用场景以及所解决的问题。如果你已经了解,那么可以跳过这一part往下看Pipeline和事务的区别。
1. Pipeline使用场景和原理
Pipeline是为了减少Redis命令多次网络传输而设计出来的客户端命令缓存功能,能够将多个Redis命令打包一次性发送给服务端,从而将多次命令的多次网络耗时压缩为1次。多条命令的响应也会打包一次性返回给客户端。
Redis命令从请求到响应的耗时由两部分组成。
一部分是命令在网络传输的耗时,对应网络IO;
一部分是命令在Redis服务端处理的耗时,对应内存IO。
假设客户端和Redis集群位于同机房或者相同局域网,一次网络IO的耗时也在大概数百微秒到几十毫秒之间,而一次内存IO的耗时则在纳秒级别。因此Redis的性能瓶颈是网络IO而非内存IO。
如果客户端要发送10条Redis命令,在不使用Pipeline的情况下,总耗时=10次网络时间+10次命令执行时间;
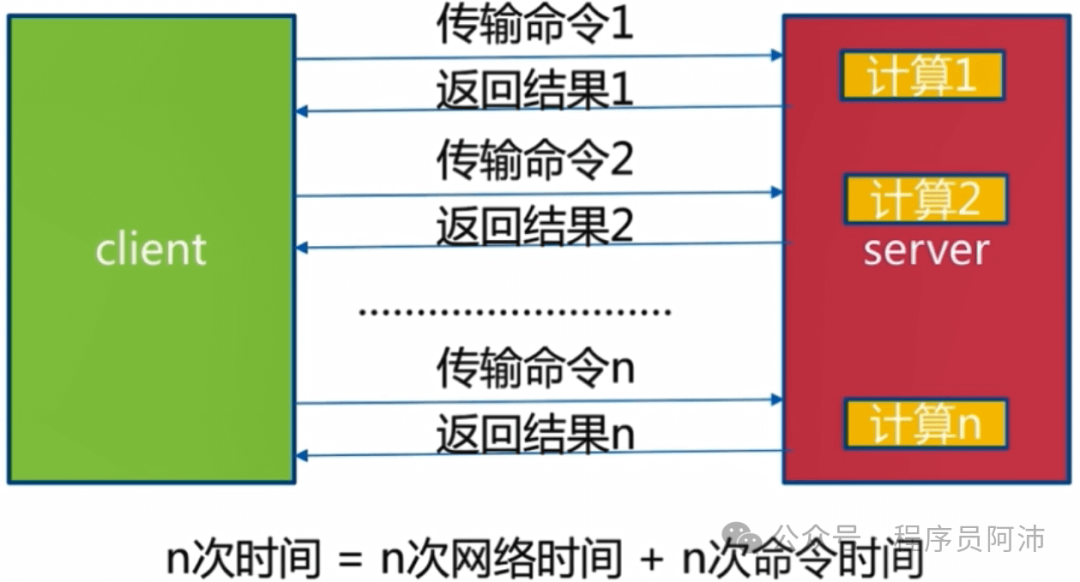
在使用Pipeline的情况下,总耗时=1次网络时间+10次命令执行时间;
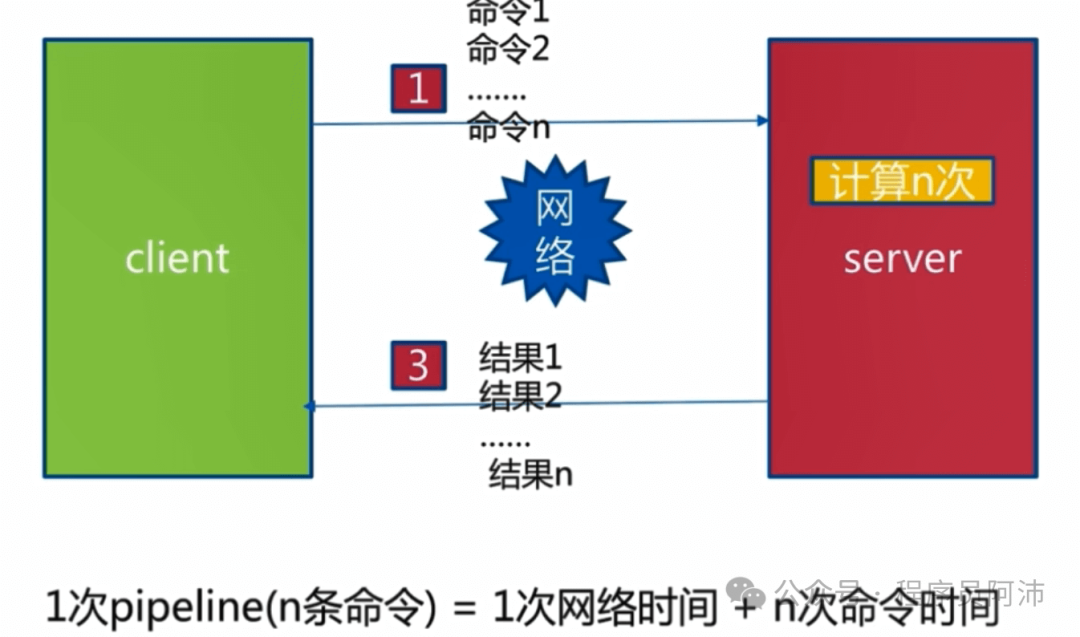
而当Pipeline中命令的数量在合理的范围内或者命令不存在长耗时命令的情况下,n次命令执行时间与1次网络时间相比是微不足道的。
下面是Pipeline的使用示例,这个示例中,客户端往使用Pipeline缓存了4条命令。
# 开启管道模式PIPELINE
# 批量设置值SET key1 value1SET key2 value2
# 批量删除键DEL key1DEL key2
# 执行管道中的所有命令EXEC
Question 1:并不是往 Pipeline 中提交和缓存的命令条数越多越好,如果往 Pipeline 提交的命令过多会有什么问题?
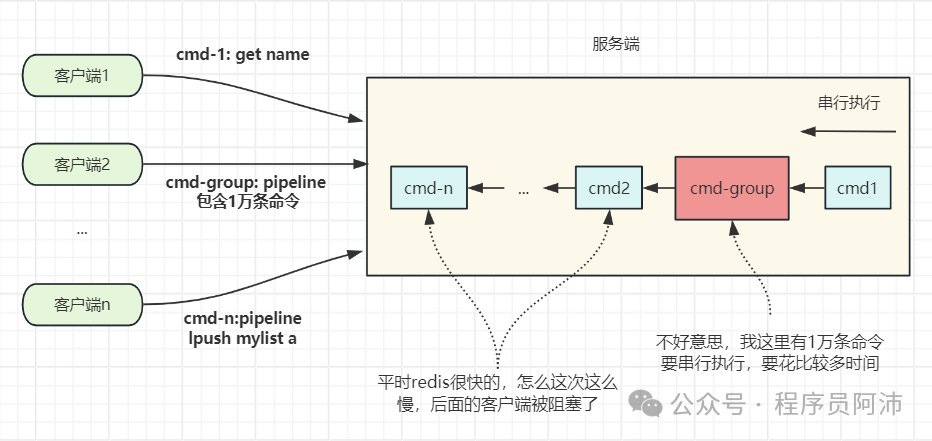
主要有两个问题。
a.
Redis执行命令是串行的,所以Pipeline的多条命令也是紧密的串行执行的,中间不会穿插执行其他客户端的命令。如果Pipeline的命令数量太多会阻塞到其他客户端的命令执行。
b. Pipeline会一次性将多条命令的响应返回给客户端,如果Pipeline的命令数量太多导致的响应数据包过大,可能会阻塞网络或者造成业务侧内存溢出。
因此正确的做法应该是将一个大Pipeline划分为多个小Pipeline发送。
Question 2:什么情况下无法使用Pipeline?
当多条命令之间存在数据依赖时,例如下一条命令的参数依赖上一条命令的返回结果,此时只能够逐条命令发送。
1. Redis事务和Pipeline的相似点和区别
相似点在于 Redis事务中的命令和 Pipeline中的命令都 会暂存起来一次性连续执行,并一次性返回多条命令的结果。
区别在于
a. 使用场景不同
Redis事务的使用场景是为了通过事务的ACID满足业务需求或者数据一致需求,而Pipeline是为了满足提高命令发送效率的需求。
Redis事务的多条命令也是客户端一次次单独发送给服务端的,并没有提升传输效率,所以Redis事务的多条命令的发送也可以结合Pipeline使用。
Pipeline中的命令间不存在某条命令执行失败,其他命令就不执行的说法,不存在原子性,和事务完全是两个概念。
b. 暂存方式不同
Pipeline中的命令是暂存在客户端,是客户端提供的功能,与服务端无关。
事务中的命令是暂存在服务端的事务队列,是服务端提供的功能。