
数据结构与算法(七)复杂度为O(nlogn)的排序——快速排序、归并排序和堆排序
01 快速排序
快排作为一种最经典的O(nlogn)复杂度的排序算法,它的思路是待排序的数组里选一个基准元素A,比A大的放A右边,比A小的放A左边。
然后再通过递归的方式对A左右两边的子序列重复上述操作。该排序法使用了分治法。
下面我们看看快排的具体过程和思路。
这里我们会运用滑动窗口的思想技巧。我们定义两个指针p1,p2,区间范围[p1,
p2]表示滑动窗口,滑动窗口被明确定义为只能放大于等于基准元素midEle的值。
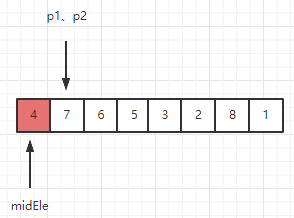
1、一开始基准元素为midEle=4, p1,p2重合,滑动窗口内初始序列为[7]。 检测新元素7 > midEle,因此 7 满足能呆在滑动窗口的条件。
p2向后移动一格,扩大窗口。
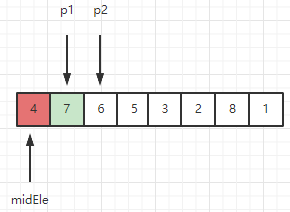
2、此时窗口内序列为 [7, 6], 检测新元素6 > midEle,因此 6 满足能呆在滑动窗口的条件。
继续如上操作,将5也纳入窗口内,当p2指到元素3的时候,往下看步骤3。
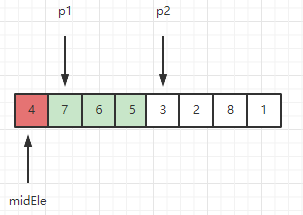
2、此时窗口内序列为 [7, 6, 5, 3], 检测新元素3 < midEle,因此 3 不满足呆在滑动窗口的条件,需要把3挪出窗口。挪动操作如下所示:
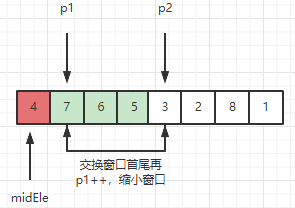
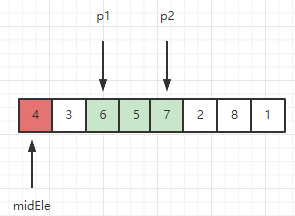
更新后,窗口为 [6, 5, 7]。
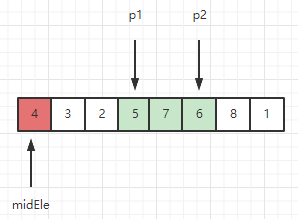
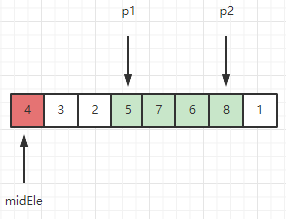
接下来重复上述过程,直到p2溢出数组。
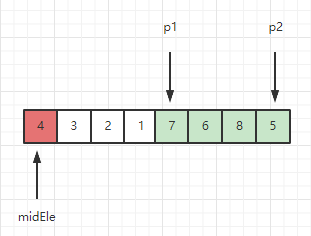
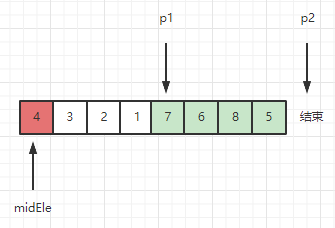
此时区间 [1, p1) 和 [7, len(arr)-1] 分别是小于midEle的部分 和 大于等于midEle的部分,需要将4放到这两个区域之间:
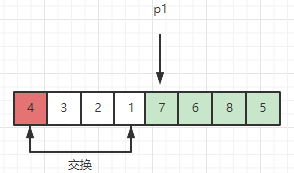
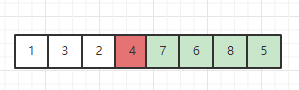
之后再对中间元素 4 以左和以右的子序列通过递归重复上述操作即可。
代码实现如下(GO语言实现):
func quickSortWin(arr []int){ if len(arr) <= 1{ return }
midEleIdx := rand.Intn(len(arr)) midEle := arr[midEleIdx] arr[0], arr[midEleIdx] = arr[midEleIdx], arr[0] var p1, p2 int // 滑动窗口,里面是大于等于midEle的元素
for p1, p2 = 1, 1; p2 < len(arr); p2++{ if midEle > arr[p2]{ arr[p2], arr[p1] = arr[p1], arr[p2] p1++ // 缩小窗口 } }
arr[0], arr[p1-1] = arr[p1-1], arr[0] quickSortWin(arr[:(p1-1)]) quickSortWin(arr[p1:])}
使用滑动窗口技巧是我能想到的最容易理解快排的方法。实际上双指针技巧和滑动窗口还可以用来解决很多其他的数组问题。
最后附上非递归版本的快排,使用栈实现
type QuickSortNode map[string]intfunc quickSortWinWithStack(arr []int){ stack := list.InitLinkedList() stackVal := QuickSortNode{"startIdx":0, "endIdx":len(arr) - 1} stack.UnShift(stackVal) var p1, p2 int // 滑动窗口
for stack.Length > 0{ curStackVal := stack.Shift().(QuickSortNode) startIdx := curStackVal["startIdx"] endIdx := curStackVal["endIdx"]
midEleIdx := startIdx + rand.Intn(endIdx-startIdx+1) midEle := arr[midEleIdx] arr[startIdx], arr[midEleIdx] = arr[midEleIdx], arr[startIdx]
for p1, p2 = startIdx + 1, startIdx + 1; p2 <= endIdx; p2++{ if midEle > arr[p2]{ arr[p2], arr[p1] = arr[p1], arr[p2] p1++ // 缩小窗口 } }
arr[startIdx], arr[p1-1] = arr[p1-1], arr[startIdx] if p1 - 1 > startIdx{ stackVal = QuickSortNode{"startIdx":startIdx, "endIdx":p2-2} stack.UnShift(stackVal) }
if p1 < endIdx{ stackVal := QuickSortNode{"startIdx":p1, "endIdx":endIdx} stack.UnShift(stackVal) } }}
快速排序的基准元素一般选取第一个元素。但如果序列是倒序的,那么 选第一个元素作为
基准元素就会发现每一轮排完之后,基准元素的左边是所有元素,基准元素的右边没有元素。此时算法复杂度会退化为O(n^2)。为了避免这种情况我们可以每次递归的时候随机取序列的一个元素为基准元素而不是取第一个元素。
02 归并排序
归并排序的思路是将一个长度为n的数组arr,分为arr[0]~arr[n/2] 和
arr[n/2]~arr[maxIndex]两组,对这两组数组分别再进行归并排序后,将这两组排好序的数组以拉链合并的方式保存在一个额外的长度为n的空数组中。
归并排序使用了递归和分治策略,递归的终止条件是"要排序的数组只有1个元素"。
这么说可能有些抽象,那么不妨看看代码。
代码实现如下:
func MergeSort(arr []int) []int{ var mergeSortHelper func(start, end int) mergeSortHelper = func (start, end int){ if start == end{ return }
mid := (start + end) / 2 // arr[mid]是左分区的最后一个元素 mergeSortHelper(start, mid) mergeSortHelper(mid+1, end)
newArr := make([]int, end - start + 1) var p, p1, p2 int for p, p1, p2 = 0, start, mid+1; p1 <= mid && p2 <= end;p++{ if arr[p1] > arr[p2]{ // 小的值先进入newArr newArr[p] = arr[p2] p2++ }else{ newArr[p] = arr[p1] p1++ } } if p1 <= mid{ // 左分组没有全部放入newArr, 需要将左分组剩余元素放入newArr for i:=p; i<len(newArr); i++{ newArr[i] = arr[p1] p1++ } }
if p2 <= end{ for i:=p; i<len(newArr); i++{ newArr[i] = arr[p2] p2++ } }
// 将newArr的值覆盖到原数组上 for i,j:=start,0; i<=end; i, j = i+1, j+1{ arr[i] = newArr[j] } } mergeSortHelper(0, len(arr)-1) return arr}
从代码可以看出,真正的排序是发生在合并两个子数组的阶段,合并阶段发生在对分组递归排序之后完成,因此归并排序本质是一个二叉树的后续遍历。
然后顺带提一嘴,快排中,将元素分为比基准元素大和比基准元素小这两个分组的过程是发生在递归之前,因此快排本质上是一个二叉树的前序遍历。
也就是说,快排是先排序后分组,归并排序时先分组再排序。
复杂度分析
可以画一个二叉树来分析代码中递归函数的调用过程,二叉树的一个节点就是一次递归。
下面这张图,未排序的数组是 [5,8,6,3,9,2,1,7],最顶层的那一行数组是已经排好序的数组,可以从底层往上看。
可以看到,从最底层开始,[5]和[8]这两个数组合并并且在合并的时候排序,可以得到[5,8];
[ 6] 和[ 3] 这两个 数组 合并 并且在合并的时候排序, 可以得到 [3 , 6];
[5 , 8] 和 [3,6] 这两个 数组 合并 并且在合并的时候排序, 可以得到[3,5,6,8]。
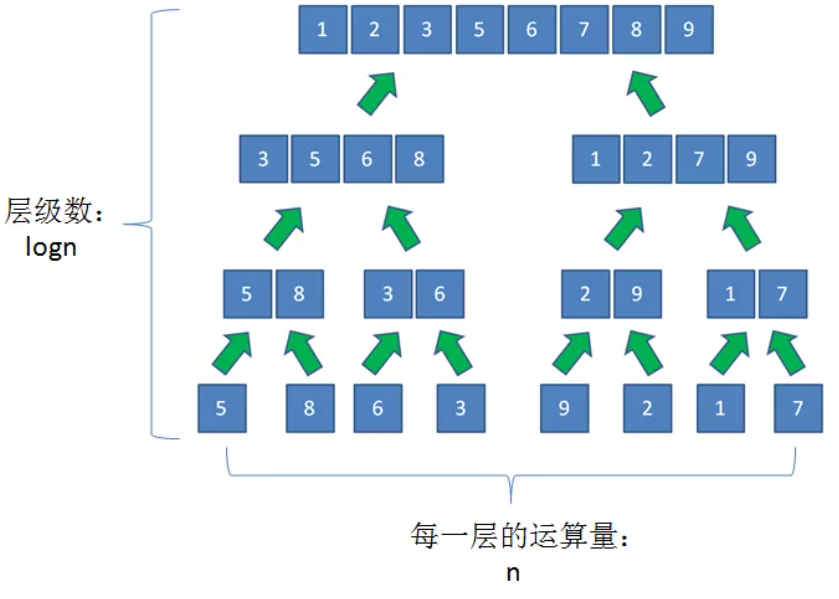
同一层的所有递归函数的运算总量为 n,树高为logn,因此时间复杂度为 O(nlogn)。同一层的所有递归函数使用的额外空间为n,总的额外使用空间为
nlogn,但是回到上一层递归时,下层递归的所有空间都已经释放,因此所有额外使用的空间不是叠加的,因此额外使用的空间最大值为n,空间复杂度为O(n)。
总结:归并排序复杂度为 O(nlogn),空间复杂度为O(n),而且是一个稳定的排序,不会出现相同值乱序的问题。
03 堆排序
堆排序顾名思义就是借助二叉堆进行排序。如果有不知道二叉堆这种数据结构的朋友可以跳转到这里:
如果需要升序排就用最大堆做堆排序
如果需要降序排就用最小堆做堆排序
回顾一下最大二叉堆的特性,最大二叉堆的顶端元素最大,而且父节点保存的元素一定大于子节点的。
那么如何使用最大堆做升序排序呢?
只需要不断让堆顶节点与未交换过的末尾节点交换,
并通过其自身下沉的特性让顶部元素到达合适的位置。让堆顶节点与未交换过的末尾节点交换就可以保证每一次交换后元素在树里面从右到左从下到上是有序的。
如下所示为一个未排好序的最大堆,这个最大堆在物理结构上表现为一个一维数组:[10,8,9,7,5,4,6,3,2],在逻辑上表现为下图的二叉树,这种物理上表现为数组,逻辑上表现为二叉树的结构就被称为二叉堆。
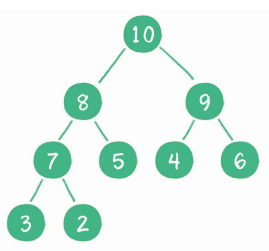
第一次交换(2和10)并下沉(2)
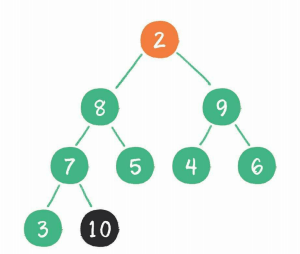
[ 10, 8,9,7,5,4,6,3 , 2 ] => [ 2, 8,9,7,5,4,6,3 , 10 ]
其中黑色表示已排序区,绿色和橙色是未排序区。
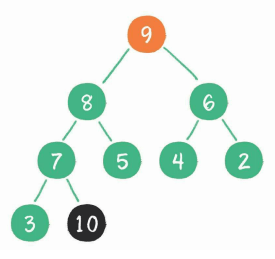
[ 2, 8,9,7,5,4,6,3 ,10 ] => [ 9 , 8,6,7,5,4,2,3 , 10 ]
第二次交换(3和9) + 下沉(3)
[ 9 , 8,6,7,5,4,2,3 , 10 ] => [ 3 , 8,6,7,5,4,2 ,9 , 10 ]
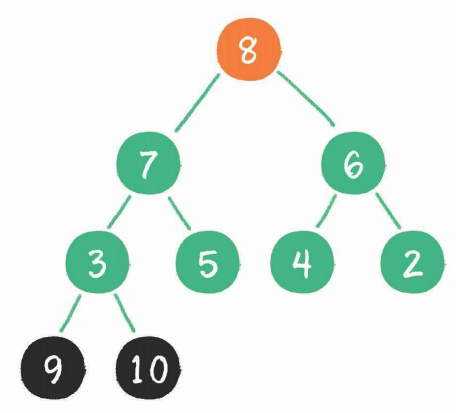
[ 3 , 8,6,7,5,4,2 ,9 , 10 ] => [ 8 ,7,6,3,5,4,2, 9, 10]
第三次交换(8和2) + 下沉(2)
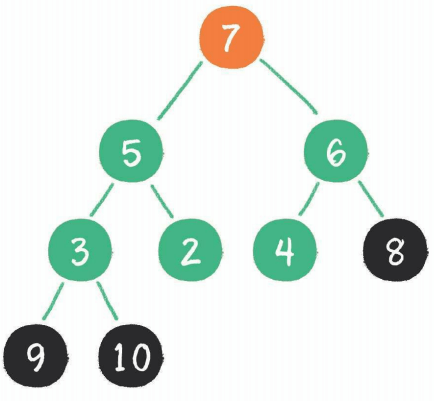
[ 8 ,7,6,3,5,4,2, 9, 10] => [ 7 , 5,6,3,2,4, 8,9,10]
最终的结果是
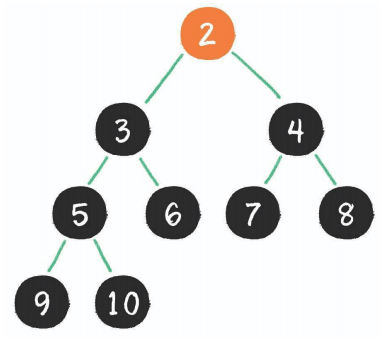
需要注意的是顶部元素不能下沉到已排好序(即黑色区域)的元素,只能下沉到未排好序的绿色区域。
代码实现如下:
func HeapSort(sl []int) (heap tree.Heap){ // 构建二叉堆 heap = tree.BuildHeap(sl) temp := 0
// 交换顶部元素 for i:=len(heap) - 1; i > 0 ; i--{ temp = heap[i] heap[i] = heap[0] heap[0] = temp
// 再未排好序的区域内下沉 tree.DownAdjustToLastIdx(heap, 0, i-1) }
return heap}
// 下沉到指定下标操作func DownAdjustToLastIdx(heap Heap, idx, lastIdx int){ // 对指定下标的节点下沉 if idx + 1 > len(heap){ // 超出范围的下标 return }
parentIdx := idx childIdx := parentIdx * 2 + 1 // 默认要替换的子节点取左节点 temp := heap[parentIdx]
for childIdx <= lastIdx{ // 如果节点还没有下沉到超过堆长度的位置就可以继续做下沉操作 // 如果有右节点而且右节点小于左节点,则取左节点替换 if childIdx + 1 <= lastIdx && heap[childIdx] > heap[childIdx + 1]{ childIdx++ }
if temp <= heap[childIdx]{ break } heap[parentIdx] = heap[childIdx] parentIdx = childIdx childIdx = parentIdx * 2 + 1 } heap[parentIdx] = temp // 不要写成heap[parentIdx] = temp,不然会超出数组范围}
该操作分为两步:构建堆(O(n))和对n-1个元素进行下沉操作(O(nlogn)),所以该排序的时间复杂度为O(nlogn)。
最后奉上所有排序的复杂度和优缺点归纳, 根据时间复杂度可以将排序算法分为 2 个梯队。
O(n^2)的排序算法比较:冒泡排序、选择排序 和 插入排序。
从性能上看,冒泡排序和插入排序的元素比较交换次数取决于原始数组的有序程度。插入排序的性能略高于冒泡排序,因为冒泡排序在每轮排序中对所有未排序区内的元素进行比较和交换,插入排序只需在已排序区找到指定位置即可停止比较,不会对整个已排序区比较,而且挪动元素的成本低于交换元素。
选择排序的比较交换次数是固定的,和原始数组的有序程度无关。
因此,当原始数组接近有序时,插入排序性能最优;当原始数组大部分元素无序时,选择排序性能最优。
从稳定性看,冒泡排序和插入排序是稳定排序,值相同的元素在排序后仍然保持原本的先后顺序。选择排序是不稳定排序。
O(nlogn)的排序算法比较:快排、堆排序、归并排序。
从性能上看,希尔排序的平均时间复杂度最快可以达到O(n^1.3),性能略低于O(nlogn)。
快速排序的平均时间复杂度是O(nlogn),但是在极端情况下(两个分区中一个分区很多元素,一边分区很少元素),最坏时间复杂度是O(n^2)。
归并排序和堆排序的时间复杂度稳定在O(nlogn)。
堆排序比归并排序和快排的性能略低一些。主要是由于二叉堆的父子节点在内存中并不连续。
根据CPU的空间局部性原理,CPU在每次访问数据的时候,会把内存中相邻的数据也一并存入缓存。这样一来,CPU以后再访问邻近的数据就不需要重新访问内存,而是访问CPU缓存,从而大大提升了程序执行的效率。因此堆排序的平均性能比快速排序和归并排序略低。
快速排序和堆排序是原地排序,不需要开辟额外空间。而归并排序是非原地排序,在merge操作的时候需要借助额外的辅助数组来完成。
从稳定性看,归并排序是稳定排序,快速排序和堆排序是不稳定排序。