
深入Redis系列(六)redis客户端和服务端围绕一条redis命令的打工人一生(一条redis命令的生命周期)

有没有想过业务侧调用了一个redis命令api之后会发生什么,这条命令是如何在客户端被处理,如何发送到服务端,服务端如何执行这一条命令。
本篇文章将介绍redis的客户端和服务端在redis运行的时候做了什么,以及一条redis命令的生命周期。
01 redis客户端
以下是redis客户端视角的自述。
我是redis客户端,应用侧想要通过我向redis服务端发送一些命令,作为工具人的我为了实现应用侧的这个愿望需要先和redis服务端发起连接。我和服务端的通信也是典型的TCP通信,在通信的过程中需要记录本次通信的一些状态和本客户端的信息。
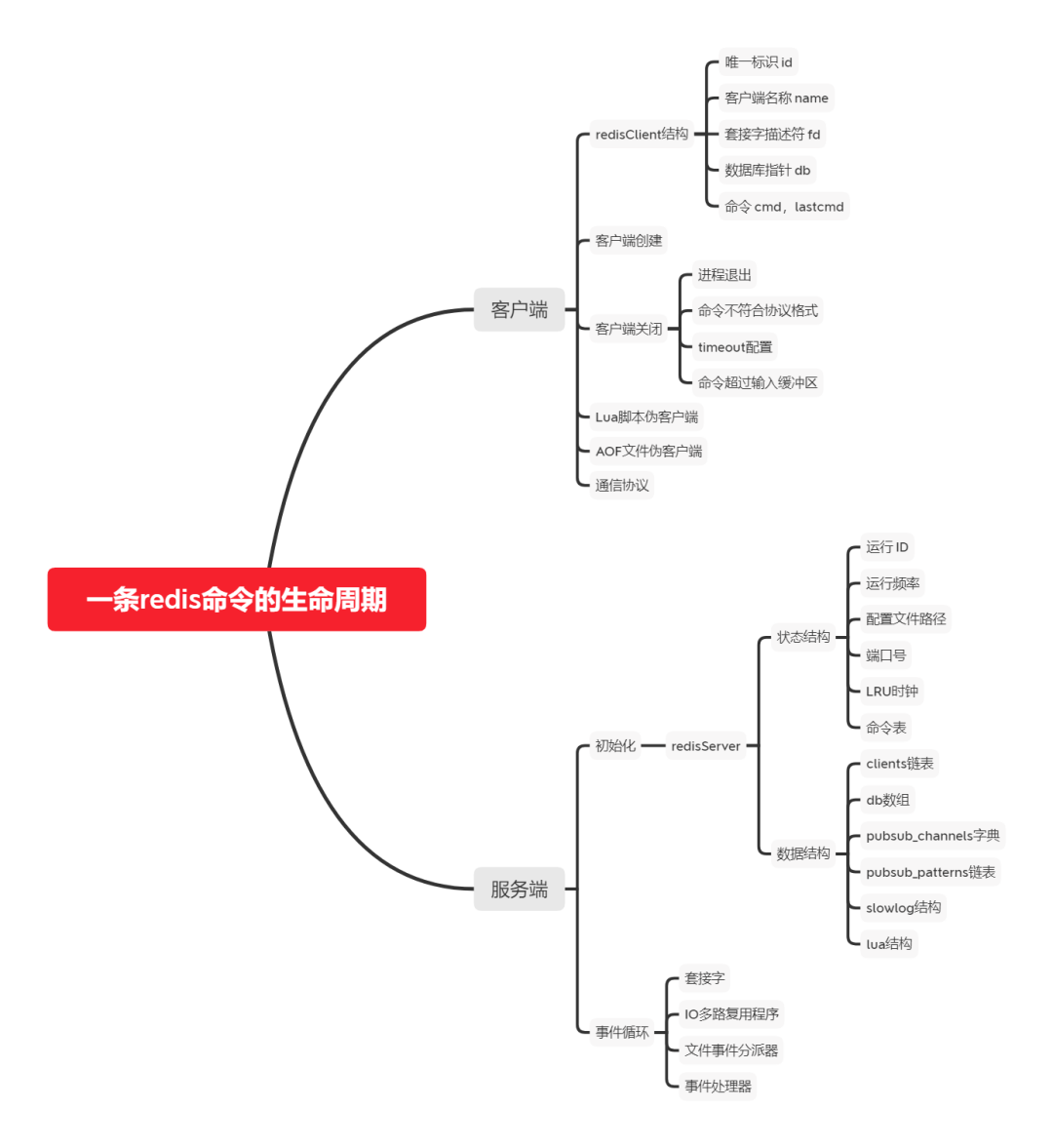
而这些状态和信息都被记录到了 一个叫做 redisClient 的结构
里面,这个结果包含客户端当前的状态信息,以及执行相关功能时需要用到的数据结构。
typedef struct redisClient { uint64_t id; /* Client incremental unique ID. */ int fd; // 客户端套接字描述符,这里的是服务器accept之后产生的副套接字 redisDb *db; // 指向数据库的指针 robj *name; /* As set by CLIENT SETNAME,客户端的名称 */ struct redisCommand *cmd, *lastcmd; // 客户端当前要执行的命令和上一次执行的命令 // ...} redisClient;
redis服务端是牛马中的牛马,与redis服务端连接的redis客户端可不止一个,这些redis客户端都想要redis服务端帮自己执行redis命令,因此redis服务器需要记录和维护有哪些redis客户端与自己发生了连接。
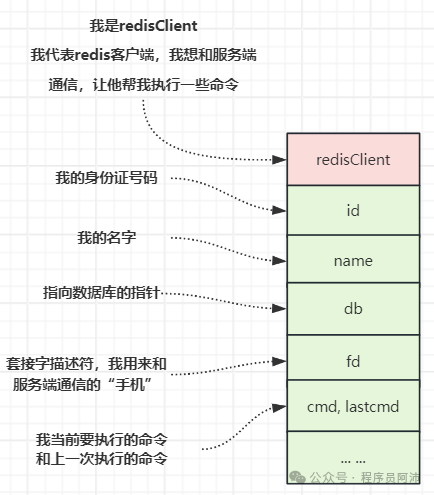
和我的redisClient结构相类似,Redis服务器也有一个redisServer的状态结构用来描述redis服务器自身的状态和信息,redisServer结构中的一个叫做clients的属性就会记录有哪些redis客户端与服务端发生了连接,clients属性是一个链表,这个链表保存了所有与服务器连接的客户端的redisClient。
redis服务器对客户端们执行批量操作,或者查找某个指定的客户端,都可以通过遍历clients链表来完成:
struct redisServer { // ... list *clients; /* List of active clients */}
Redis客户端属性
作为客户端,我包含以下内容。
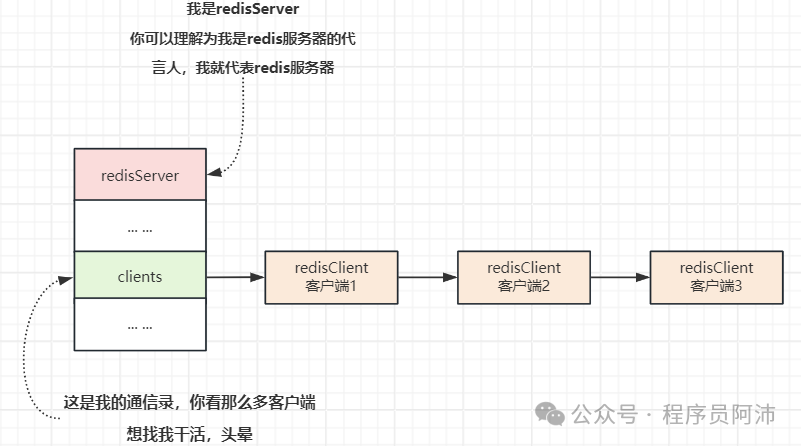
1. 我的套接字描述符
我的fd属性记录了我正在使用的套接字描述符,通过这个描述符我可以控制用于和服务端通信的网络套接字,我们姑且将其视作为是一部和服务端通信的“手机”。
根据客户端类型的不同,fd属性的值可以是-1或者是大于-1的整数:
伪客户端(fake client)的fd属性的值为-1:伪客户端处理的命令请求来源于AOF文件或者Lua脚本,而不是网络。
大家可以理解为,服务端除了要处理我们客户端发送过去的命令之外,还需要执行一些保存在服务端自己存储的一些命令(如上面所提到的AOF文件和Lua脚本),而执行命令就需要用到客户端,此时服务端会生成一个为客户端来发送这些服务端自身存储的的命令请求。
由于是执行服务端自己存储的命令,因此不需要进行通 信,也就不需要这部所谓的“手机”和控制这部“手机”的fd属性,因此fd属性会被设置 为-1。
目前Redis服务器会在两个地方用到伪客户端,一个用于载入AOF文件并还原数据库状态,而另一个则用于执行Lua脚本中 包含的Redis命令。
普通客户端的fd属性的值为大于-1的整数:像我们普通客户端就会使用大于-1的fd属性来记录客户端套接字的描述符,从而控制套接字来与服务器进行通信。
下面是创建一个redisClient结构的过程。
// networking.c/createClientredisClient *createClient(int fd) { // 创建客户端 redisClient *c = zmalloc(sizeof(redisClient)); if(fd != -1) { // 不是-1,则为普通客户端,执行下列代码 // 非阻塞 anetNonBlock(NULL,fd); // 非延时 anetEnableTcpNoDelay(NULL,fd); // keepalive if(server.tcpkeepalive) anetKeepAlive(NULL,fd,server.tcpkeepalive); // 创建文件事件:绑定读事件,且处理函数为readQueryFromClient if(aeCreateFileEvent(server.el,fd,AE_READABLE,readQueryFromClient,c) == AE_ERR) { close(fd); zfree(c); return NULL; } } // 设置客户端对象的信息 selectDb(c,0); c->fd = fd; // 设置客户端套接字 // ... return c;}
通过执行 CLIENT list 命令可以列出目前所有连接到服务器的普通客户端,命令输出中的fd显示了服务器连接客户端所使用的套接字描述符:
redis> CLIENT listaddr=127.0.0.1:53428 fd=6 name= age=1242 idle=0 addr=127.0.0.1:53469 fd=7 name= age=4 idle=4 ...
2.我的名字
唉,作为工具人,在默认情况下,我是没有名字的。
redisClient *createClient(int fd) { // ... c->name = NULL; // ...}
3. 我的 标志
客户端的标志属性flags记录了客户端的角色(role),以及客户端目前所处的状态。
下面是我的一些标志的例子:
REDIS_SLAVE (1<<0) /* 我是个从服务器的客户端 */REDIS_MASTER (1<<1) /* 我是个主服务器的客户端 */REDIS_MONITOR (1<<2) /* 我是一个监控从服务器的监控节点的客户端 */REDIS_MULTI (1<<3) /* 我是一个事务上下文的客户端 */...
4.我的输入缓冲区
要执行的命令在通过套接字发送给服务端之前,会先进入到我的输入缓冲区暂存(也就是我redisClient的querybuf属性),否则这些命令就会以一次请求只发送一个字符的方式发送到服务端,既容易丢失效率又低,还不如先把这些命令攒到缓冲区再一次性发送给服务端。
typedef struct redisClient { // ... sds querybuf; // 输入缓冲区 // ...} redisClient;
我和服务端之间的消息需要遵循一定的格式协议,服务端只读得懂按照我们约定好的协议所封装的消息。
这个消息协议的一般形式是这样的:
*<参数数量> CR LF$<参数 1 的字节数量> CR LF<参数 1 的数据> CR LF...$<参数 N 的字节数量> CR LF<参数 N 的数据> CR LF
例如发送命令:
SET mykey myvalue
那么这串命令的打印版本为:
*3$3SET$5mykey$7myvalue
实际传输给服务端的内容为:
*3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$7\r\nmyvalue\r\n
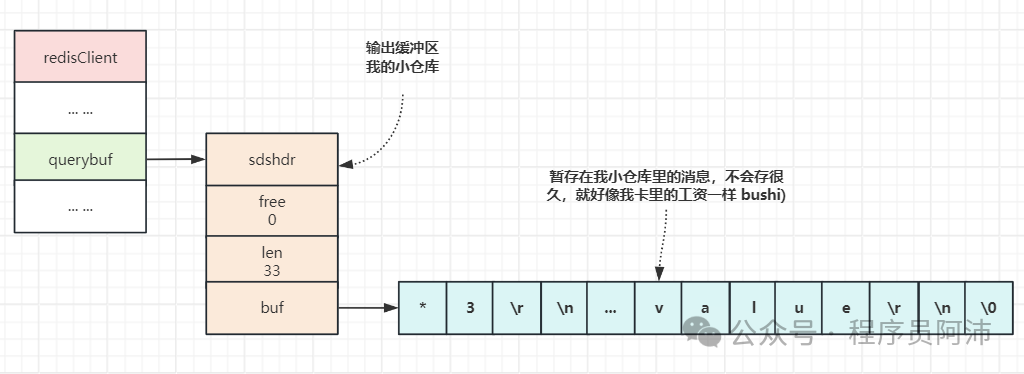
我和服务器发送的命令或数据一律以\r\n (CRLF)结尾。
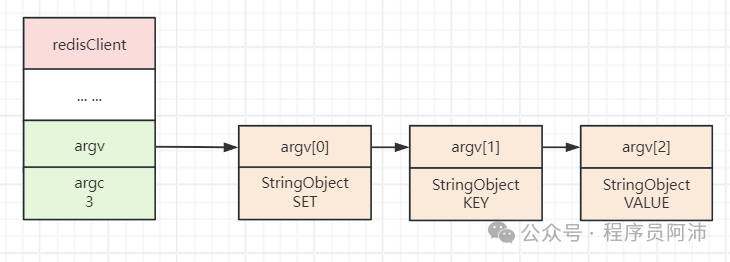
5.命令与命令参数
在服务器将我发送的命令请求保存到我的querybuf属性之后,服务器将对命令请求的内容进行分析,并将得出的命令参数以及命令参数的个数分别保存到我redisClient的argv属性和argc属性:
typedef struct redisClient { robj **argv; int argc;} redisClient;
以上面的命令为例,服务器分析输入缓冲区的内容后,创建如图所示的argc和argv:
6.命令的实现函数
当服务器从协议内容中分析并得出 argv 属性和
argc属性的值之后,服务器只是知道了命令的内容,但是还不知道他应该根据这个命令做些什么事情。服务器将根据项argv[0]的值,在命令表中查找命令所对应的命令实现函数,这些实现函数会指导服务器具体是要存一个东西还是取一个东西。
下图展示了一个命令表的示例,该表的数据结构是一个字典,字典的键是一个SDS结构,保存了命令的名字,字典的值是命令所对应的redisCommand结构。
是的,redis命令也有自己的结构redisCommand,就像我客户端有redisClient结构,服务端有redisServer结构一样。
redisCommand这个结构保存了命令的实现函数、命令的标志、命令应该给定的参数个数、命令的总执行次数和总消耗时长等统计信息。
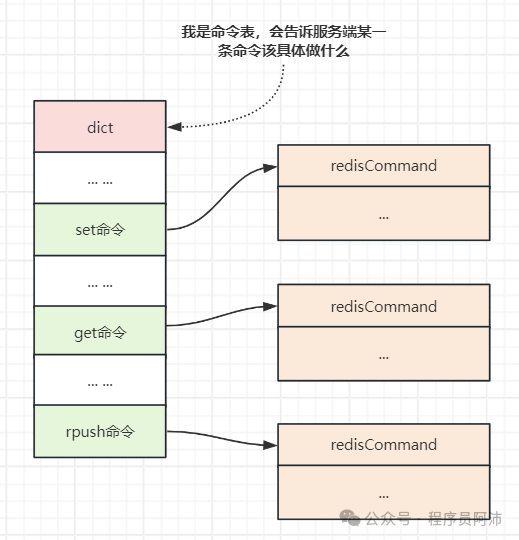
当程序在命令表中成功找到 argv[0]所对应的redisCommand结构时,它会将我redisClient的cmd指针指向这个结构:
struct redisCommand *cmd;
之后,服务器就可以使用cmd属性所指向的redisCommand结构,以及argv、argc
属性中保存的命令参数信息,调用命令实现函数,执行客户端指定的命令。
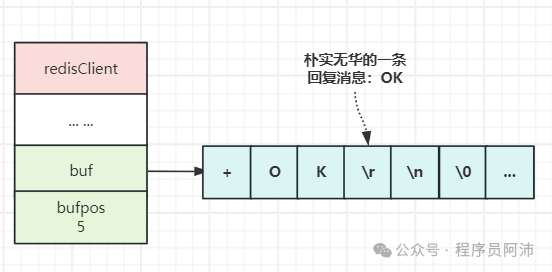
7.输出缓冲区
服务端执行命令所得的命令回复会被保存在我客户端状态的输出缓冲区里面,每个客户端都有两个输出缓冲区可用,一个大小是固定的,一个是可变的。
// 固定缓冲区int bufpos; // 记录了buf数组目前已使用的字节数量char buf[REDIS_REPLY_CHUNK_BYTES]; // 输出缓冲区,缓存向客户端发送的数据
下图展示了一个使用固定大小缓冲区来保存返回值+OK\r\n的例子。
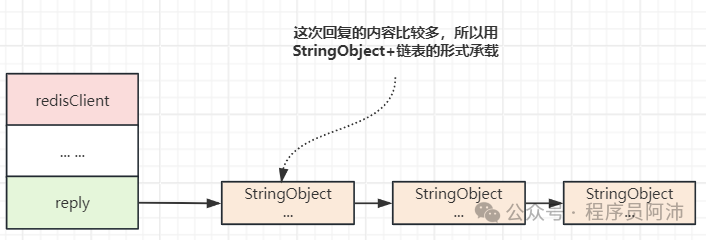
list *reply; // 可变缓冲区
下图展示了一个使用可变缓冲区来保存较长返回值的例子。
Redis 命令会返回多种不同类型的回复。
通过检查服务器发回数据的第一个字节, 可以确定这个回复是什么类型:
状态回复(status reply)的第一个字节是 “+”
错误回复(error reply)的第一个字节是 “-”
整数回复(integer reply)的第一个字节是 “:”
批量回复(bulk reply)的第一个字节是 “$”
多条批量回复(multi bulk reply)的第一个字节是 “*”
客户端的创建与关闭
1.我的创建
如果我是那种通过网络连接与服务器进行连接的普通客户端,那么在本客户端使用connect函数连接到服务器时,服务器就会调用连接事件处理器,为我创建相应的客户端状态(即redisClient结构),并将这个新的客户端状态添加到服务器状态结构
clients 链表的末尾。
2.我的关闭
一个普通客户端可以因为多种原因而被关闭:
如果我的客户端进程退出或者被杀死,那么客户端与服务器之间的网络连接将被关闭,从而造成客户端被关闭,可以理解为我被炒鱿鱼了。
如果我向服务器发送了带有不符合协议格式的命令请求,那么本客户端也会被服务器关闭,可以理解为我做错事被炒鱿鱼了。
用户可以为服务器设置timeout配置选项来指定本客户端的最大空转时间,当本客户端的空转时间超过timeout
选项设置的值时,我将被关闭,可以理解为我摸鱼的时间太长又被炒鱿鱼了。
不过timeout
选项有一些例外情况:如果我是主服务器和从服务器用来保持心跳通信的客户端,或者是正在被BLPOP等命令阻塞,或者正在执行SUBSCRIBE、PSUBSCRIBE这样需要等待的订阅命令,那么即使我的空转时间超过了timeout
选项的值,我也不会被服务器关闭,可以理解为我在奉旨摸鱼。
如果我发送的命令请求的大小超过了输入缓冲区的限制大小(默认为1GB),那么这个我也会被服务器关闭,可以理解为用户一次性要我发送给服务器执行的命令太大了,我受不了不干了。
3. Lua脚本的伪客户端
服务器会在初始化时创建负责执行Lua 脚本中包含的Redis命令的伪客户端,并将这个伪客户端关联在服务器状态结构的lua_client属性中:
struct redisServer { redisClient *lua_client;}
lua伪客户端在服务器运行的整个生命期中会一直存在,只有服务器被关闭时,这个客户端才会被关闭,是个干到公司倒闭才休息的哥们。
4.AOF文件的伪客户端
服务器在载入AOF文件时,会创建用于执行AOF文件包含的Redis命令的伪客户端,并在载入完成之后,关闭这个伪客户端。
02 redis服务器
以下是redis服务端视角下的自述。
我是redis服务端,如何接收和发送命令客户端已经说完了,我接收命令和发送执行结果的过程也和客户端收发消息的过程一致,这里就不啰嗦了。客户端以为我只是单纯执行一条条他们发送过来的指令,但是不知道我要接收不止一个客户端的请求,也不知道我除了执行命令之外还要持久化数据、做内存管理、给从服务器同步消息等工作。
其他的先不说,只说我开工初始化的过程、执行命令相关的工作和如何应对那么多个客户端的请求。
初始化服务器
初始化服务器状态结构
初始化我自己的第一步就是创建一个struct redisServer类型的实例变量server作为我的状态,并为结构中的各个属性设置默认值。
初始化server变量的工作由一个叫initServerConfig的函数来完成, 主要工作有:
设置我的运行 ID
设置我的默认运行频率
设置我的默认配置文件路径
设置我的运行架构
设置我的默认端口号
设置我的默认RDB持久化条件和AOF持久化条件
初始化我的LRU时钟
创建命令表
由initServerConfig函数设置的属性基本都是一些整数、浮点数、或者字符串属性,除了命令表之外,initServerConfig函数没有创建redisServer中的其他数据结构,如数据库、慢查询日志、Lua环境、共享对象等。这些数据结构在之后的步骤才会被创建出来。
初始化服务器数据结构
在之前执行initServerconfig函数初始化server状态时,程序只创建了命令表一个数据结构,不过除了命令表之外,我还包含其他数据结构,比如:
server.clients链表,这个链表记录了所有与我相连的客户端,链表的每个节点都包含了一个redisClient结构实例。
server.db数组,数组中包含了我的所有数据库。
server.pubsub_channels字典, 用于保存频道订阅信息。
server.pubsub_patterns链表, 用于保存模式订阅信息。
server.lua结构, 用于执行Lua脚本的Lua环境。
server.slowlog结构, 用于保存慢查询日志的属性。
当初始化进行到这一步,我将调用initServer函数,为以上提到的数据结构分配内存,并在有需要时,为这些数据结构设置或者关联初始化值。
之所以到现在才初始化数据结构的原因在于,本服务器必须先载入用户指定的配置选项,然后才能正确地对数据结构进行初始化。
除了初始化数据结构之外,initServer还进行了一些非常重要的设置操作,其中包括:
a.设置进程信号处理器:可以接收用户的信号,例如把我关掉的信号…。
b.创建共享对象:这些对象包含Redis服务器经常用到的一些值,比如包含”OK”回复的字符串对象,包含”ERR”回复的字符串对象,包含整数1到10000的字符串对象等等,服务器通过重用这些共享对象来避免反复创建相同的对象,既可以节省内存又可以节省时间,蚊子再小也是肉,我也算是勤俭持家的好牛马了…。
c.打开我的监听端口,并为监听套接字关联连接应答事件处理器,等待服务器正式运行时接受客户端的连接,打开监听端口我才能接收客户端的连接和命令请求。
d.为servercron函数创建时间事件,等待服务器正式运行时执行serverCron函数。
关于文件事件、时间事件和事件处理器可以参考上一篇文章:
深入Redis系列(五)Redis事件机制详解 IO多路复用、文件事件、时间事件、reactor模式
e.如果AOF持久化功能已经打开,那么打开现有的AOF文件,如果AOF文件不存在,那么创建并打开一个新的AOF文件,为AOF写入做好准备。
关于AOF持久化,可以参考这一篇文章,这里不再赘述:
深入Redis系列(三)redis持久化之RDB快照持久化和AOF日志持久化
f.初始化服务器的后台I/O模块(bio),为将来的I/O操作做好准备。
当initServer函数执行完毕之后,服务器将在日志中打印出Redis的图标,以及Redis的版本号信息。
在初始化的最后一步,本服务器将打印出以下日志:
[5244] 21 Nov 22:43:49.084*The server isnow ready to accept connections on port 6379
这个时候就是我开始被迫营业的时候…
服务器的初始化工作进入尾声,下一步本服务器开始可以接受客户端的连接请求,并处理客户端发来的命令请求了。
执行事件循环
接下来我开始执行服务器的事件循环(loop),揭秘我一个服务端能处理那么多客户端请求的关键就在这里。
假如有100个客户端,每个客户端以1秒100个命令的速度发送请求,请问如果是你,阁下该如何应对?
在你的想象中,我可能是这样子:
先问客户端1有没有命令请求到达?有就一次性拿走所有客户端1的命令,然后1条条命令执行。没有就再问客户端2。
然后问客户端2有没有命令请求到达?有就一次性拿走客户端2的命令,然后1条条命令执行。没有就再问客户端3。
…
但是通过这种遍历一个个客户端套接字,查看每个套接字的缓冲区是否有命令到达的方式太慢,等不到第2秒我就会被用户炒鱿鱼。
其实我的瓶颈不在于执行命令,而在于如何快速接收多个客户端的命令,也就是说我的瓶颈在于网络IO而非CPU,执行命令是纯内存操作,在处理命令的时候即使是单线程一条条命令查命令表执行也很快,还不用担心并发写数据引起的脏数据和加锁问题。
为了快速接收多个客户端的命令,我发明了一个叫做事件处理器的东西,采用操作系统中一种叫做IO多路复用和事件循环的技术来监听多个客户端套接字,让事件处理器告诉我哪个客户端发来了命令消息,而不用我主动的问一个个套接字有没有命令到达,这样我就可以专心负责执行命令,解放双手了。
什么是事件?什么是事件处理器呢?什么是事件循环?
发起连接、写入、读取、关闭连接都是一种事件。redis中的
事件是对套接字操作的抽象,每当一个套接字准备好执行连接、写入、读取、关闭等操作时,就会产生一个文件事件,也称之为某某事件就绪。
因为本服务端通常会连接多个套接字,所以多个文件事件有可能会并发地出现。
而事件处理器就是专门处理这些就绪事件的事件处理程序。就例如,有客户端的命令到达本服务端,就是一个读取事件,而且这个读取事件已经就绪。而所谓的事件处理就是指我应该从客户端套接字的缓冲区拿走这个命令消息。
下面是文件事件处理器的构成和工作流程。
文件事件处理器由四部分组成: 套接字、 IO多路复用程序、 文件事件分派器、 事件处理器。
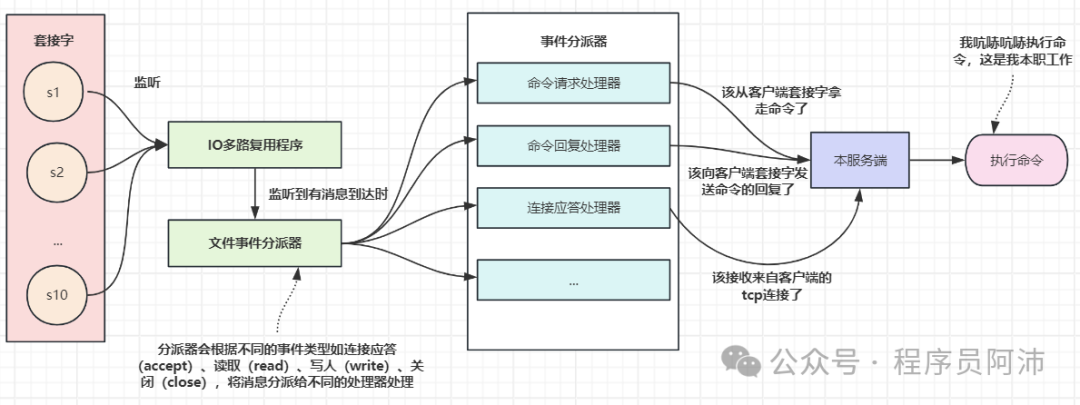
就像我刚刚说的,事件处理器会监听这些套接字并告诉我那些套接字的消息就绪了,这么一来我就知道哪些消息就绪,但问题是事件处理器自己是怎么知道有哪些消息就绪了的呢,难道有人告诉他?
还真有,操作系统的IO多路复用程序会告诉他。
如果说文件事件处理器是我的下属,和我是一路人,那么操作系统就是一个独立于我之外的个体,一个暖男兼管理员,为所有像我这样的用户进程提供帮助。我们可以理解为是操作系统帮我们遍历这些套接字从而检查出有哪些套接字就绪的,至于他是一个个套接字遍历的(select系统调用),还是更高效的遍历(epoll系统调用,红黑树+就绪队列),就不在本次的讨论范畴了。
尽管就绪的多个文件事件可能会并发地出现,但IO多路复用程序总是会将所有产生事件的套接字都放到一个队列里面,然后通过这个队列,以有序、同步、每次一个套接字的方式向文件事件分派器传送事件就绪的套接字(也就是有消息的套接字)。当上一个套接字产生的事件被处理完毕之后(该套接字所关联的事件处理器执行完毕),IO多路复用程序才会继续向文件事件分派器传送下一个套接字。

回到什么是事件循环这个问题,
事件循环本质上是一个死循环代码,对于操作系统而言,事件循环是操作系统所执行的一个不断检测套接字是否已就绪的死循环。对于本服务端来说,事件循环就是我自己所执行的一个不断从事件分派器那里获取事件,处理事件和执行命令的死循环。
如果没有任何客户端向我发起连接或者发送命令请求,那么我的这个事件循环会被阻塞住,我也就可以摸摸鱼了。
如果有客户端发起命令请求,这条命令信息就会被我的事件循环捕获到,我再从客户端套接字取走这条命令并查命令表执行它。
至此,我的初始化工作圆满结束,一条redis命令也在上述过程中被执行处理。