
数据结构与算法(六)复杂度为O(n^2)的排序——冒泡排序、选择排序、插入排序 和 希尔排序
前言:
距离上一次更新已经接近一年了,之所以那么长时间没更新有两个原因。一个是工作太忙,去年年末的时候脱离业务组进入基建组做一些基建项目,每周末加班连轴转,不过好在从中学到了不少东西可以分享给大家;另一个原因是繁忙但枯燥的工作以及接近30岁却依旧迷茫的情绪让我逐渐对技术失去热情。
我在思索,技术人到底如何挺过35岁大关,也许这也是大家平时偶尔会思考但没多久就又会被做不完的工作所掩埋的问题。直到这两天重新打开手机看到没有更新却依旧涨粉的公众号,我知道我的分享是能帮助到大家的,这让我决心复更。
公众号对我而言,也许能得到什么是一件未知的事,但至少让我回想和复盘过往学过什么,以及学习过程中get到的快乐,朝闻道夕死可矣相信痴迷过学习的人都曾有过这样的体会,不仅局限于技术,也包括生活、职场、感情等。所以之后的更新内容,可能我不再局限于技术,但我相信只要是真诚的分享和有用有趣的内容,同样也能吸引到有趣的你们。
我是从未停止过学习的阿沛,最后还是希望所分享的内容能帮到大家,你们的肯定是我最大的动力。
从这一节开始,我们将介绍排序算法不同的排序算法有不同的时间复杂度和空间复杂度,并且在不同的排序场景下,排序性能也不尽相同。这里我们将会按不同的时间复杂度将排序算法分成两期介绍。本期将介绍时间复杂度为O(n^2)的排序算法,下一期介绍时间复杂度为O(nlogn)以及线性复杂度的排序算法。
01 冒泡排序法
现在我们我们要对一个数值型数组内的数值进行排序,冒泡排序的过程本质上是元素在这个数组中比较大小和交换位置的过程,下面的文字可以结合的图片一起看。
原数组:

假如数组arr,长度为n,冒泡排序需要交换n-1轮,每一轮的交换过程要借助相邻的两个指针p1,p2(初始状态下p1=0,
p2=1),把相邻的这两个指针指向的元素进行两两比较。
当arr[p1]>arr[p2]则交换两个元素的位置,当p[1]<=p[2]时则不交换位置,比较完之后p1,p2指针往后移动,
这样我们可以始终保持p2位置的元素大于p1元素。
如下图所示,绿色区域是未排序区域,紫色是已排序区域。
当p2到达未交换区域的尾部,且本轮排序完成了最后一次p1和p2的交换后,p2就是未排序区中最大的元素,此时p2位置可归入 已排序区域,表示该元素已排好序
。
一轮排序:
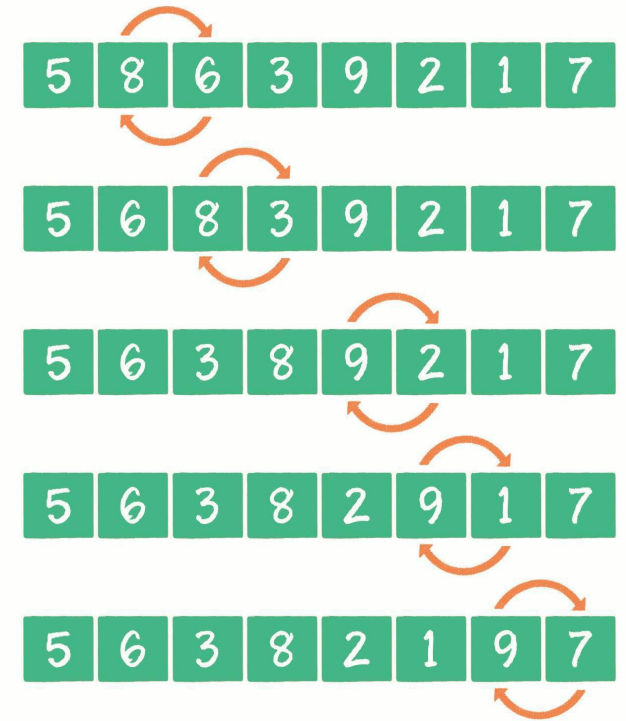

剩下的几轮排序:

下面是代码实现(GO语言实现):
func BubbleSort(arr []int) []int{ if len(arr) <= 1{ return arr }
end := len(arr) - 1 // end是未排序区的最后一个位置 time, p1, p2 := end, 0, 1 // time是剩余要交换的轮数 for time > 0 { time-- for p2 <= end{ if arr[p1] > arr[p2]{ arr[p1], arr[p2] = arr[p2], arr[p1] } p1++ p2++ } p1 = 0 p2 = 1 end-- } return arr}
冒泡排序 其本质就是使用了前后双指针的技巧,这种写法是最容易理解的。
另一种写法则是递归写法:
func BubbleSort3(arr []int){ // 该函数明确定义为:对完全未排序区域数组arr进行一轮排序 if len(arr) <= 1{ return }
end := len(arr) - 1 p1, p2 := 0, 1
// 开始本轮交换 for p2 <= end{ if arr[p1] > arr[p2]{ arr[p1], arr[p2] = arr[p2], arr[p1] } p1++ p2++ }
// 交换完一轮之后,通过递归交换下一轮,是一个前序遍历,但未排序区要缩小 BubbleSort3(arr[:end])}
下面是传统的写法:
func BubbleSort(sl []int) []int{ for i:=1; i<=len(sl)-1; i++{ // 遍历n-1个节点(或者说要进行n-1轮排序) temp := 0 for j:=0; j<len(sl) - i; j++{ // 每遍历一个节点要交换或比较n-i次, j是当前遍历到的节点下标 if sl[j] > sl[j+1]{ temp = sl[j+1] sl[j+1] = sl[j] sl[j] = temp } } } return sl}
无论是哪种写法,都是外层循环控制交换的轮数,内层循环实施每一轮交换的具体操作。
下面是冒泡排序的几种优化。
优化1:
下面我们看看冒泡排序的优化,当完成了第6轮排序时,数组就已经排好了,但代码还是会去执行第7轮排序。
此时可以做个标记,如果某一轮交换中实现交换的次数为0则表示数组已经排好序,就无需完成剩下的几轮排序。
优化2:
考虑下面这种情况

对于这样的一个数组而言,5678已经排好序,未排序的区域是前四个元素,按照冒泡排序算法,需要排序n-1=7轮。但实际如果只关注真正的未排序区,我们只用排序3轮。
此时我们需要找到这个有序区和无序区的边界并标记下来即可。
针对优化1和2的代码如下:
func BubbleSortImprove(arr []int) []int{ if len(arr) <= 1{ return arr }
end := len(arr) - 1 // end是未排序区的最后一个位置 p1, p2 := 0, 1 // time是剩余要交换的轮数 for end > 0 { // 当未排序区的分界下标end就是数组的第一个元素,即未排序区只有一个元素时,就可以停止下一轮交换 fmt.Println(end) nextEnd := end - 1 exchangeTime := 0 // 交换次数 for p2 <= end{ if arr[p1] > arr[p2]{ arr[p1], arr[p2] = arr[p2], arr[p1] nextEnd = p1 // 只要交换了就说明分界要更新 exchangeTime++ } p1++ p2++ } if exchangeTime == 0{ // 如果某轮交换的交换次数为0,说明数组已经排好序 return arr } p1 = 0 p2 = 1 end = nextEnd } return arr}
该做法增加了两个变量 nextEnd 和exchangeTime分别用来优化第二点和第一点。
优化3:
考虑一种情况,如果一个序列大部分元素已经排好序,按照传统的冒泡排序会执行很多无用的排序,如下所示

2~7其实已经排好了,但是冒泡排序依旧会执行7轮排序。但如果从右往左冒泡排序的话,排两轮就可以完成。
为了优化这种情况,有人提出了鸡尾酒排序,其本质也是冒泡排序,按照第一轮从左到右排,第二轮从右到左排,像钟摆一样反复。
使用鸡尾酒排序,3轮冒泡就能排好。
func BubbleSortImprove2(sl []int) ([]int){ temp := 0 for i:=1; i<=len(sl)/2; i++{ sorted := true for j:=i; j<len(sl)-i; j++{ // 从左到右排序 if sl[j] > sl[j+1]{ temp = sl[j+1] sl[j+1] = sl[j] sl[j] = temp sorted = false } } if sorted { break } sorted = true for j:=len(sl)-i; j>i; j--{ // 从右往左排序 if sl[j] < sl[j-1]{ temp = sl[j-1] sl[j-1] = sl[j] sl[j] = temp sorted = false } } } return sl}
02 选择排序法
选择排序的思路如下(如果看不懂这段话,就从”用最简单的话来说“那里看起):
使用相邻的双指针p1, p2(初始p1=0,
p2=1)做多轮交换和比较。p1在每轮固定在未排序区的最左侧不移动,而p2每次往右移动一格,并与p1的值进行比较,如果p2的值更小,则p1和p2所在的值做一次交换,当完成一轮比较和交换之后,最左侧的p1元素就是最小的值,p1变为已交换区,第一轮比较和交换完成。
第一轮比较和交换完成后,p1指针往右移动一格,p2回到p1的右边相邻的位置,此时p1又重新位于未排序区的第一个元素,接着完成第二轮比较和交换,直到所有元素排好序。
用最简单的话来说就像我们打牌,一般都是从左到右数,把最小的那张拿出来放到最左边,再对剩下的牌重复这个过程即可。
对比选择排序和冒泡排序
相同点:
1、冒泡排序和选择排序的比较次数相同总共为 n*(n-1)/2次(都需要进行 n-1 轮比较,每轮进行平均 n /
2次比较),但是选择排序的每轮交换次数小于冒泡排序。
2、选择排序在数组包含多个相同值时,可能打乱相同值之间原有的顺序,而冒泡排序不会。下图为选择排序打乱相同值的一个例子(下图中是先将较小值放到前面,因此前面是已排序区,后面是未排序区):
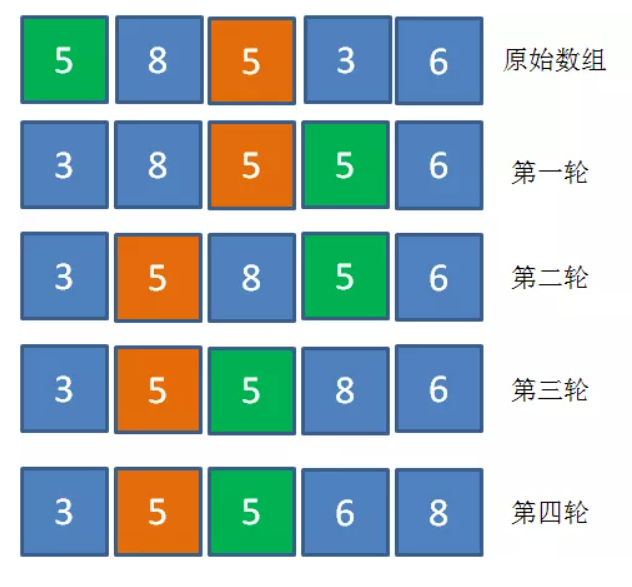
最终结论是:
通常情况下,选择排序由于交换次数少,性能略高于冒泡排序。但在要求保证相同值间原有顺序的特殊场景下必须使用冒泡排序。
此外,冒泡排序在“数组中的大部分元素有序”时,它的 交换次数会少很多 ,而选择排序的交换次数稳定为n-1,因此该情景下,冒泡排序的效率比选择排序高。
03 插入排序
插入排序的思路是创建一个初始指向arr[0]的指针p,将数组arr分为:左边的已排序区(arr[0]至arr[p],不包含p) 和
右边的未排序区(arr[p]至arr[max])。arr[p]是下一个要排好序的元素。
对arr进行n-1轮排序,每轮排序需要将arr[p]插入到排序区的合适位置。怎么理解这个最合适位置呢,举例说明,
过程如下,紫色为已排序区,蓝色为未排序区:
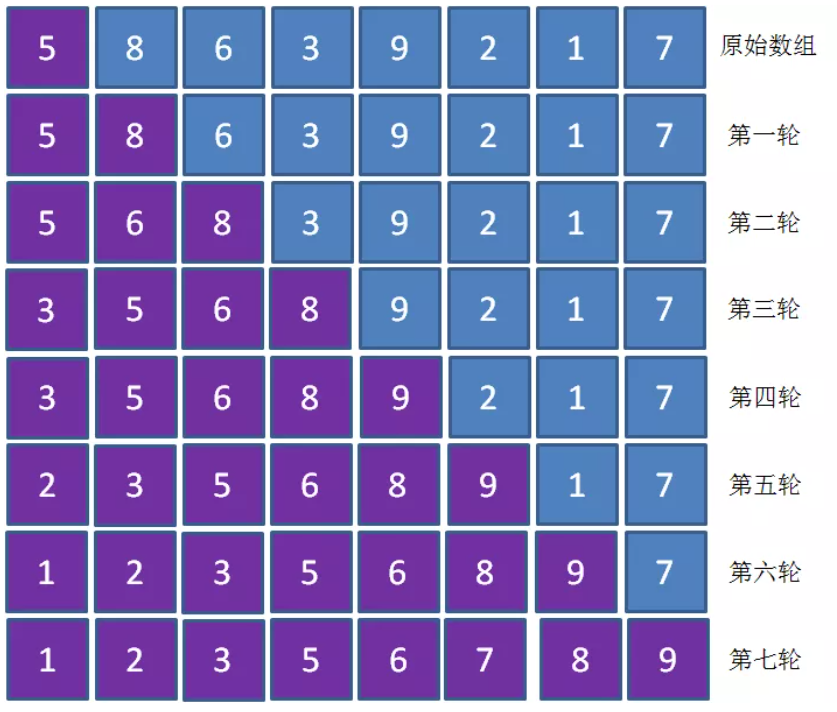
第一轮排序,会先遍历到8,8最合适的位置在5之后,8已经位于最合适的位置因此不需要移动。
第二轮排序,会先遍历到6,6最合适的位置在5和8之间,因此6会插入到5和8之间的位置。
第三轮排序,会先遍历到3,3最合适的位置在5之前,因此3会插入到5之前的位置。
以此类推。
但是把3插入到5之前的这个过程不是一个一步到位的过程,因为数组是一种紧凑的数据结构,如果不借助多一个数组作为额外空间的话,就只能通过交换元素的方式实现所谓的“插入”。也就是需要先将3和8交换,再将3和6交换,再将3和5交换,这样才能做到把3插入到5的前面。
代码实现:
func InsertSort(arr []int) []int{ p := 0 for p < len(arr){ target := arr[p] // 要插入到已排序区的目标值 i := p-1 // target要和[0, p-1]的数比较,从而找到要插入的位置,比较的同时要将arr[i]挪到arr[i+1]的位置 for ; i >=0; i--{ if target < arr[i]{ arr[i+1] = arr[i] }else{ // 如果 arr[i] 比 arr[p]小或相等,则arr[p]插入到arr[i+1]的位置 break } } arr[i+1] = target p++ } return arr}
但相比于冒泡排序,插入排序不仅减少了很多次交换,也减少了很多次比较。
如果在数组大部分元素是有序的情况下,插入排序的比较次数和交换次数都可以大大减少,对一个完全排好序的数组进行插入排序其复杂度为O(n),这是优于选择排序和冒泡排序的地方。
04 希尔排序
希尔排序是基于插入排序的优化, 其大体思路是将一个数组预处理,使其满足下述两点 :
1、插入排序在数组长度越小的情况工作量越小;
2、插入排序在数组大多数元素已经有序的情况下工作量越小(对于完全排好序的数组,插入排序只需比较 n-1次,而且无需交换,无需移动元素)。
具体思路是对数组arr进行多轮不同间距的分组,初始间距为len(arr)/2,下一轮的间距是上一轮间距的一半(如果无法整除则向下取整)。
对同一间距下的每个分组进行插入排序,当间距减小为1时整个数组arr就只有一组,即arr本身,对arr本身进行最后一次插入排序即可完成整体排序。(间距越大,每一组的元素数量就越小,反之则每一组的数量越大,实际上组数
= 间距,即使间距/2无法整除这个结论也成立)。
过程如下:
0、原数组arr

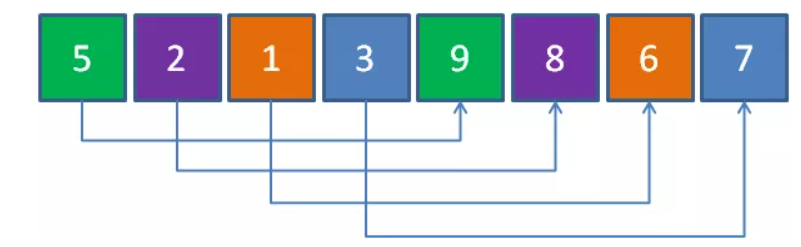
1、第一轮间距取 len(arr)/2 = 4,共4组,每组2个元素(组数 = 间距 = 4)
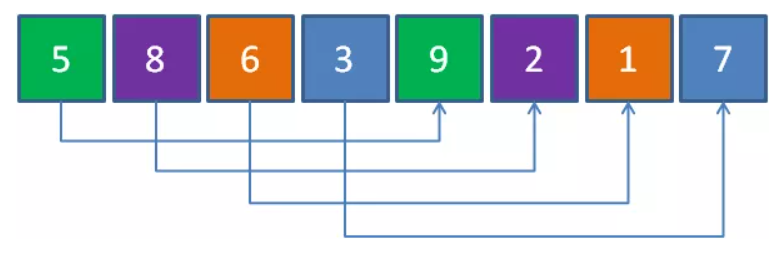
元素5和元素9一组,元素8和元素2一组,元素6和元素1一组,元素3和元素7一组,一共4组。对每组进行插入排序后的结果如下:
2、第二轮间距取 len(arr)/2^2 = len(arr)/4 = 2,共2组,每组4个元素
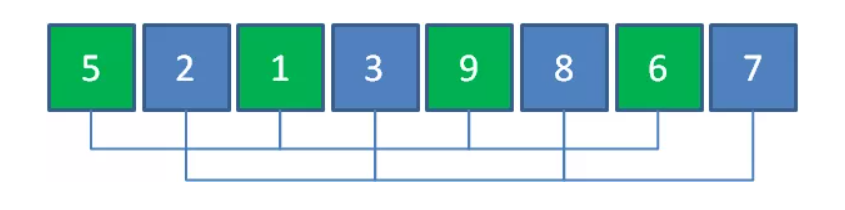
元素5,1,9,6一组,元素2,3,8,7一组。对每组进行插入排序后的结果如下:
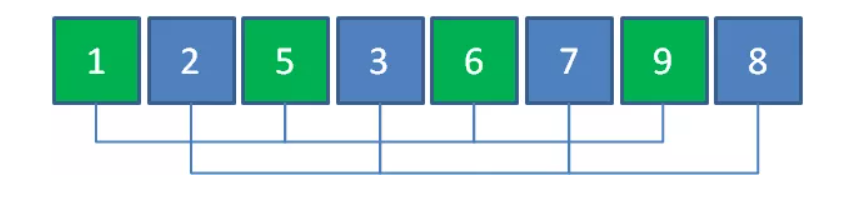
3、第三轮间距取 len(arr)/8 = 2,共1组,每组8个元素,进行最后一次插入排序

分组可以减少每次插入排序的元素数量,满足第一个优化条件;下一轮分组的插入排序都是在上一轮已经有部分排序的序列中再排序,满足第二个优化条件。
上面示例中所使用的分组跨度(4,2,1),被称为希尔排序的增量,又称为希尔增量。实际上对增量的选择不同,希尔排序的性能也不同。
代码实现:
// 希尔排序func ShellSort(arr []int) []int{ gap := len(arr)/2 // gap表示组间距 for gap >= 1{ // 在指定组间距下,arr[0:gap]是每一组的第一个元素,一共有 gap 组 for i:=0; i<gap; i++{ // 对 gap 组序列分别进行插入排序 InsertSortHelper(arr, i, gap) } gap /= 2 } return arr}
func InsertSortHelper(arr []int, start, gap int){ // 分组插入排序,start是本组的开始下标,gap是组间距 p := start for p < len(arr){ target := arr[p] i := p - gap // i表示没有与target比较过的已排序区元素 for ; i>=start; i-=gap{ if target < arr[i]{ arr[i+gap] = arr[i] }else{ break } } arr[i+gap] = target p += gap }}
希尔排序的复杂度介于 O(n^2)到O(nlogn)之间,最优可达到O(nlogn)的复杂度。
但是希尔排序的性能会在某种特殊情况下达到O(n^2),而且会比插入排序性能还差,那就是在分组已经排好序的情况,例如:

上面这个数组,如果我们照搬之前的分组思路,无论是以4为增量,还是以2为增量,每组内部的元素都没有任何交换。一直到我们把增量缩减为1,数组才会按照直接插入排序的方式进行调整。
对于这样的数组,应该直接使用插入排序,希尔排序不但没有减少直接插入排序的工作量,反而白白增加了分组操作的成本。
可以使用“互质(互为质数)”的增量避免这种情况,也就是增量之间没有除1之外的公约数。如 1/3/7/15,即本轮间距为 n,下一轮间距是
(n+1)/2-1,而非n/2。利用此种增量方式的希尔排序,最坏时间复杂度是O(n^(3/2))。
此外,希尔排序还是一个可能导致相同元素乱序的排序,如下:
原数组:

经过希尔排序之后得到:

由此可见希尔排序是一个不稳定排序。