
数据结构与算法(一) 线性数据结构之数组、链表、队列和栈(Go语言实现)
操作系统、计算机组成、网络和数据结构与算法是程序员的四门必会基本功,今天开始我们开启数据结构与算法的专题,我们将会围绕着时间复杂度或者空间复杂度介绍各种常见数据结构和算法的优劣以及适用场景。该专题的所有代码将由Go语言实现。
我们可以简单的把内存看成是一系列连续的以字节为单位的存储空间组成的大存储空间,每一个字节为单位的小存储空间都有一个32位或64位的内存地址。
当需要存储多项数据时,我们可以使用两种基本的数据结构:数组和链表。而 实际上我们可以认为所有数据结构一共只有数组和链表这2种
,因为所有数据结构如树、图、散列表、队列和栈等都是以数组和链表为基础构建而成的。
01 数组
数组是在内存中 连续存储的有限个相同类型的变量组成的集合。数组中的每个元素在内存 中是紧密排列 的,而且
由于元素的类型相同,因此每个元素的长度相同。
下图为数组在内存中的存储形式:
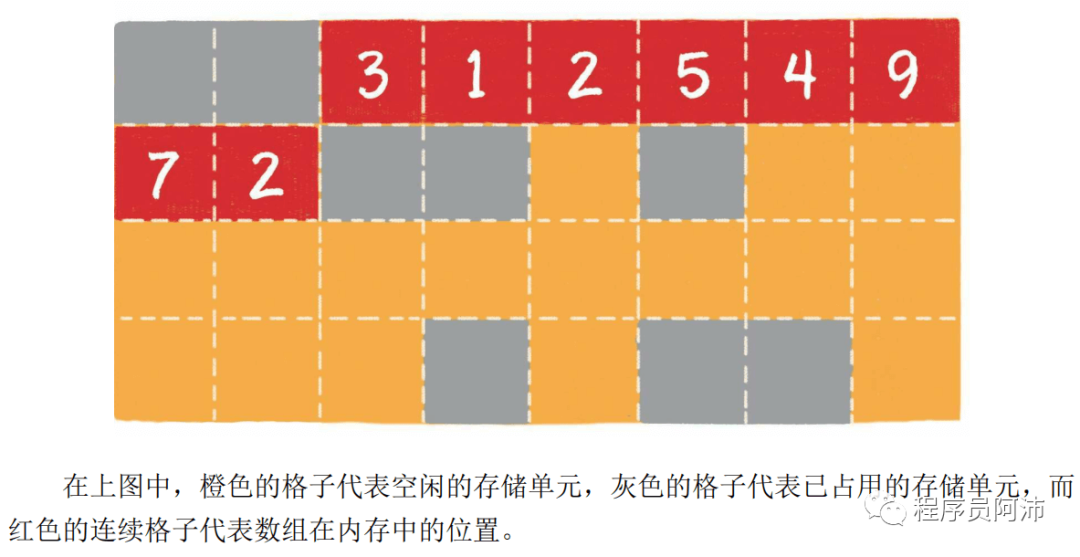
不同类型的数组,每个元素占用的字节数不同,例如对于int16类型的数组,每个元素会占2个字节(即上图中的2个小格子);对于char类型的数组,每个元素会占1个字节即图中的1个小格子。
创建一个数组需要指定数组元素的个数和类型,计算机会根据类型和元素个数计算这个数组需要占用多少字节的内存空间(即占用多少个小格子),然后向计算机申请一块连续的n个字节的空闲空间存放这个数组。
** ** ·数组增删改查 ** **
** 查找 **
每一个数组元素都有一个下标表示该元素的位置,通过某个下标(假设该下标为k)计算机会根据数组的开始地址(即数组第一个元素的开始地址,假设是x)、下标索引(k)和元素的长度(假设是4字节)计算出该元素的开始地址(x+4k),从而查到该元素的内容。
因此计算机能以O(1)复杂度读取数组的任意一个元素,而无需从数组的第一个元素往后读取到第k个元素。这种读取方式叫做 ** ** 随机读取 **
** ,随机读取的复杂度为O(1)。
** 更新 **
更新一个元素其实就是先查找后更改,因此复杂度就是查找的复杂度,为O(1)。
** 插入 **
插入需要考虑3种情况:
1、尾部插入(插入后元素个数没有超过数组长度),复杂度O(1)

2、中间插入(插入后元素个数没有超过数组长度),该操作会导致插入位置之后的元素全部后移一个元素的长度,复杂度为O(n)
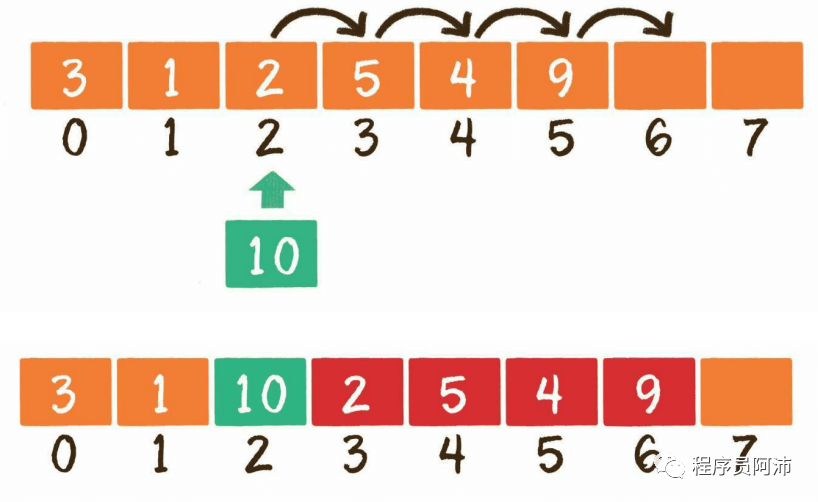
3、超范围插入(插入后元素个数超过数组长度),该情况在插入前需要先判断插入后元素个数是否会超过数组长度,如果超过则需要先对数组扩容,假设扩容默认扩为原数组2倍。扩容操作本质上是在空闲内存中找一块大小为原数组2倍的空间,并拷贝原数组空间的所有元素到新空间,将新数组的指针赋值给变量,最后释放旧数组的空间。该操作涉及所有元素的拷贝,复杂度为O(n)。
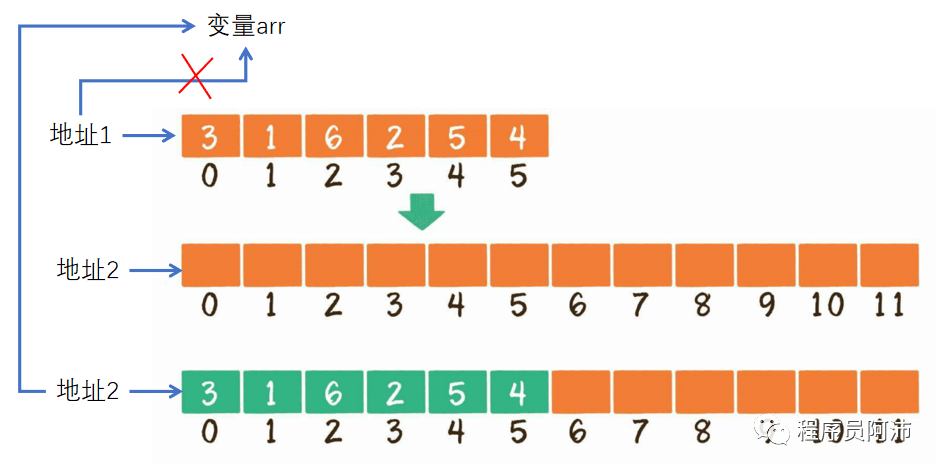
计算复杂度是以最坏复杂度为准,因此插入的复杂度是O(n)。如果不分配额外的空间就会导致内存空间溢出,可能会意外的修改到其他变量内存空间的内容。
删除
分两种情况:删除的元素是尾部元素O(1) 和 删除的元素是中间元素O(n),后者涉及到后面元素的左移。所以删除的复杂度是O(n)。
考虑一种取巧的删除方式,假如删除某个元素后不要求保持数组的顺序,我们可以将尾部元素覆盖到要删除的元素,再删除尾部元素,此时复杂度为O(1)。
· 数组优势
随机访问,查询和更改单个元素为常量级时间复杂度。二分查找法就是利用了数组的随机访问特性,每次定位到中间元素的复杂度为O(1)。
· 数组劣势
插入和删除元素导致后面的元素移动,并可能需要重新分配内存空间导致整个数组的拷贝,效率较低。
数组存储字符串
我们知道一些强类型语言中数组元素的类型必须是一致的,每个元素长度是定长的,正因如此,数组才能实现O(1)的随机查找。
那么有没有想过一个数组如何存储多个字符串,我们知道每一个字符串的长度是不同的,此时多个长度不同的字符串该如何被存到数组中?
首先我们要知道一个字符串是如何被存储的,这里假设我们存的字符串都是英文。
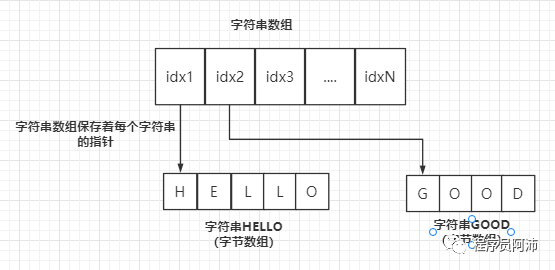
一个字符串由多个字符组成(char类型,占1字节),字符串就是一个字符类型的数组。
一个数组保存多个字符串,只需让这个数组的 元素存储这些字符数组的指针即可。指针的长度都是一致的,统一是4字节(32位)或8字节(64位)。
02 链表
链表是一种由多个节点组成的在逻辑上连续,物理上非连续的数据结构。单向链表的节点包括值和指向下一个节点的指针这2部分。
下图是单项链表在内存中的存储形式
可以看出每个节点元素不是紧密相连的(随机存储),甚至于每个节点的长度可以是不同的,占的内存块不同。
由于链表的每个节点是随机的存在内存的各个地方,因此无需分配给链表大块的空闲空间,而是利用起零散的碎片空间。

** ** ·(单向)链表增删改查 ** **
一般我们构建一个单向链表结构的时候,需要创建两个结构体:链表节点和链表。在结构体中保存指向第一个节点的指针。
查询某个节点
需要从头部开始顺着指针往后遍历直到找到指定节点,复杂度O(n)
更新某个节点
需要先查询到指定节点再修改节点值,复杂度O(n)
插入节点 有 3种情况:
-
头部插入,只需将新节点的向后指针指向头部节点,并将头部指针指向新节点,复杂度O(1)
-
中间插入,需要找到指定插入的位置(即先查询),再修改中间节点的指针指向新插入的节点,复杂度O(n)
-
尾部插入,假如在没有保存尾部节点指针的情况下,需要遍历到尾部节点才能将新节点添加到尾部,复杂度为O(n)。保存了尾部节点指针的情况下复杂度为O(1)。
和数组不同的是由于是使用零散空间存储,没有预先定义指定长度,所以无需考虑扩容。
删除节点与插入节点相似,也是3种情况,这里不再赘述。
需要注意的是,删除某个节点其实就是让其前后节点的指针不再指向该节点,在许多高级语言中我们不用可以释放被删除节点,只要没有指针指向他们,该节点会被自动回收。
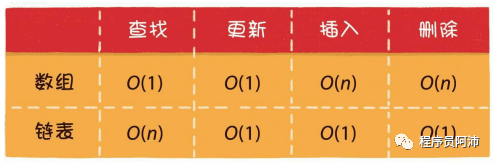
数组和链表都是线性数据结构,下面是数组和链表的操作时间复杂度(链表更新不考虑先查询的情况下):
·总体比对
1.数组需要分配连续的内存空间,且插入元素需要考虑扩容问题;链表节点是非连续存储,无需考虑扩容。
2.数组查找效率高(随机访问),插入和删除效率较低;链表查找效率低(顺序访问),从头部和尾部插入节点效率高。
3.链表需要占用额外的内存保存连接节点的指针。
一般我们将数组和链表看作是其他数据结构的物理结构。例如树这个逻辑结构,它既可以使用数组构建,也可以用链表构建。
03 栈与队列
栈是一种具有先进后出的线性数据结构,常见操作是入栈(push)和出栈(pop)。可以使用链表或数组实现。最早进入的元素存放的位置叫作栈底(bottom),最后进入的元素存放的位置叫作栈顶(top)。
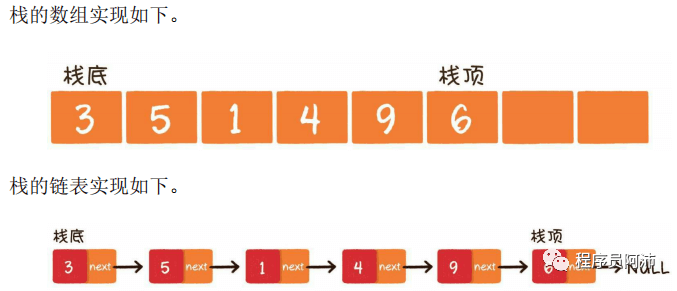
对于数组和链表(知道尾部节点地址的情况下),入栈和出栈都是O(1)复杂度。
队列是一种先进先出的线性结构,队列的 出口端叫作队头(front),队列的入口端叫作队尾(rear)。可以使用链表或数组实现。
下面是以数组为基础的队列:

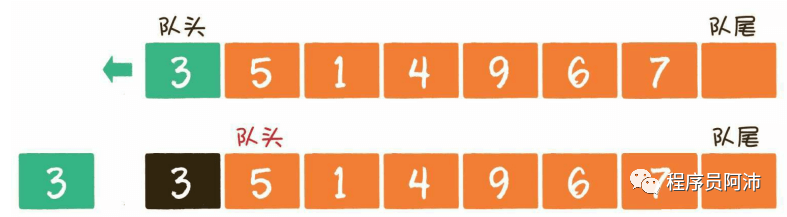
很简单,我们不对数组中的元素做移位操作,而是用两个指针标记队头和队尾。当有元素从队头弹出,就将队头指针移向下一个下标位置。当有元素入队则放到数组后面,如果数组后面的位置满了而队头前的元素位置变成空闲的位置,这个元素就放到前面这些空闲位置,而此时队尾也会移向前面的这个新加入的元素所在下标。
如果队列数组放满了元素之后还要再放入元素,则对数组扩容,并将旧数组的内容拷贝到新数组上。
如下图所示


继续放入 8 5 1 4。

需要注意的是,队尾指针是不指向任何元素的,数组需要留出一个位置不存储任何元素。当整个队列满了之后,此时可以有两种策略,一种是扩容,一种是队尾的元素覆盖队首的元素。
结合队列和栈的特点,既能先进先出,也能先进后出的数据结构是双端队列。
双端队列也是可以用数组或队列为基础。如果以数组为基础,依旧是使用循环队列的思路进行入队出队和入栈出栈。如果是以链表为基础,只需为节点加上向前和向后两个指针即可。
下面是用双端队列(链表)实现的一个队列
/** 链表节点 **/type IntNode struct{ // 值为整型的链表节点 Prev *IntNode // 向前指针 Next *IntNode // 向后指针 Key int // key Val int // 值}
func InitIntNode(key, val int) *IntNode{ node := IntNode{Key:key, Val:val} return &node}
/** 双向链表 **/type DoubleLinkedList struct{ Head *IntNode // 头部节点 Tail *IntNode // 尾部节点 Length int // 节点数}
func initDoubleLinkedList() *DoubleLinkedList{ linkedList := DoubleLinkedList{} linkedList.Head = &IntNode{} // 虚拟头尾节点 linkedList.Tail = &IntNode{} linkedList.Head.Next = linkedList.Tail linkedList.Tail.Prev = linkedList.Head return &linkedList}
// 移除某个节点func (ll *DoubleLinkedList) remove(node *IntNode) *IntNode{ if node.Prev != nil{ node.Prev.Next = node.Next }
if node.Next != nil { node.Next.Prev = node.Prev }
ll.Length-- return node}
// 从头部弹出一个节点func (ll *DoubleLinkedList) shift() (deleteNode *IntNode){ if(ll == nil || ll.Length == 0){ return }
return ll.remove(ll.Head.Next)}
// 往后插入一个节点func (ll *DoubleLinkedList) append(key, val int) *IntNode{ if(ll == nil){ ll = initDoubleLinkedList() }
node := InitIntNode(key, val) ll.appendNode(node) return node}
func (ll *DoubleLinkedList) appendNode(node *IntNode) *IntNode{ if(ll == nil){ ll = initDoubleLinkedList() }
lastNode := ll.Tail.Prev lastNode.Next = node ll.Tail.Prev = node node.Prev = lastNode node.Next = ll.Tail ll.Length++ return node}
func (ll *DoubleLinkedList) getHead() *IntNode{ if ll.Length == 0{ return nil } return ll.Head.Next}
func (ll *DoubleLinkedList) getTail() *IntNode{ if ll.Length == 0{ return nil } return ll.Tail.Prev}
代码中在头部和尾部加了两个虚拟节点,通过虚拟节点可以在入队和出队以及在链表中间插入节点时减少很多 边界条件的判断
(例如当链表只有一个节点时弹出节点,或者链表没有节点时链入一个节点)。这是实现链表的有用小技巧。
接下来我们思考一个有意思的问题,如何用栈实现一个队列,以及如何用一个队列实现一个栈呢?
· 用队列实现栈
队列实现栈比较简单,入栈时和正常的队列入队没有区别,但出栈时需要把除了队尾最后一个元素之外的其他所有元素出队并且全部按出队顺序入队。这么一来队首元素就是原本的队尾元素,也就是容器中最新的那个元素,将这个元素出队即可实现逻辑上的出栈。
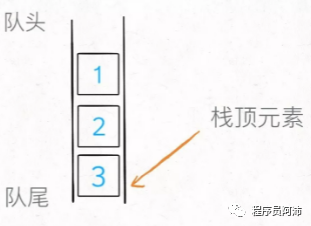
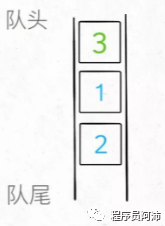
实现如下:
package practice
import "container/list"
type StackByQueue struct{ queue *list.List // 单向链表实现的队列 lastNode *list.Element // 栈顶节点}
func InitStackByQueue() *StackByQueue{ return &StackByQueue{queue:list.New()}}
func (this *StackByQueue) Enqueue(val int){ this.queue.PushBack(val) this.lastNode = this.queue.Back()}
func (this *StackByQueue) Dequeue() *list.Element{ if this.queue.Len() == 0{ return nil } for this.lastNode != this.queue.Front(){ popNode := this.queue.Front() this.queue.MoveToBack(popNode) } enqueueNode := this.queue.Front() this.queue.Remove(enqueueNode) this.lastNode = this.queue.Back() return enqueueNode}
func (this *StackByQueue) Len() int{ return this.queue.Len()}
· 栈实现队列
使用两个栈可以实现一个队列,假设栈为S1和S2,S1只负责接收入队元素(模拟队尾),S2只负责把元素出队。入队操作就是把元素入栈S1,当出队时需要从S2出栈,如果S2没有元素,则从S1出栈所有元素并放入到S2,这么一来栈S1的元素就会按照相反的顺序被存放到S2中,使得S2出栈时会先出栈早入队的元素实现先进先出。
入队时
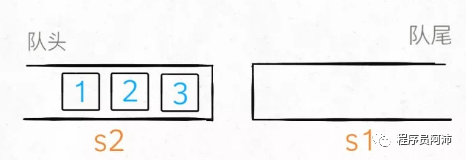
出队时
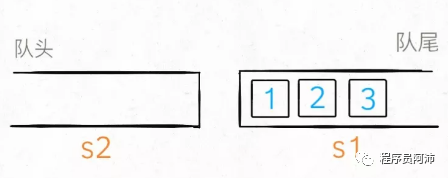
代码实现:
import "zbp_struct/struct/list"
// 用栈模拟队列type QueueByStack struct{ StackForIn *list.LinkedList // 入队栈 StackForOut *list.LinkedList // 出队栈 Length int}
func InitStackQueue() (qbs *QueueByStack){ stackForIn := list.InitLinkedList() stackForOut := list.InitLinkedList() return &QueueByStack{ StackForIn: stackForIn, StackForOut: stackForOut, }}
func (qbs *QueueByStack) Enqueue(val interface{}){ qbs.StackForIn.UnShift(val) qbs.Length++}
func (qbs *QueueByStack) Dequeue() (val interface{}) { if qbs.Length == 0{ return nil }
if qbs.StackForOut.Length == 0 { // 如果出队栈没有元素则将入队栈的元素转移到出队栈 for qbs.StackForIn.Length > 0 { qbs.StackForOut.UnShift(qbs.StackForIn.Shift()) } } qbs.Length-- return qbs.StackForOut.Shift()}