
操作系统入门(十一) 文件系统篇之文件的物理结构、磁盘结构、磁盘调度算法、随机IO和顺序IO
前文链接:
操作系统入门(十) 文件系统篇之文件与目录的逻辑结构、文件索引节点
01 文件的物理结构
文件的物理结构研究的是 已分配给文件的磁盘块在磁盘中如何组织起来的,分为连续分配、链式分配和索引分配3种。
我们知道文件可以分为逻辑上有结构的文件(记录式文件)和逻辑上无结构的文件(流式文件),但是即使是逻辑上无结构的文件在物理上也是有结构的。
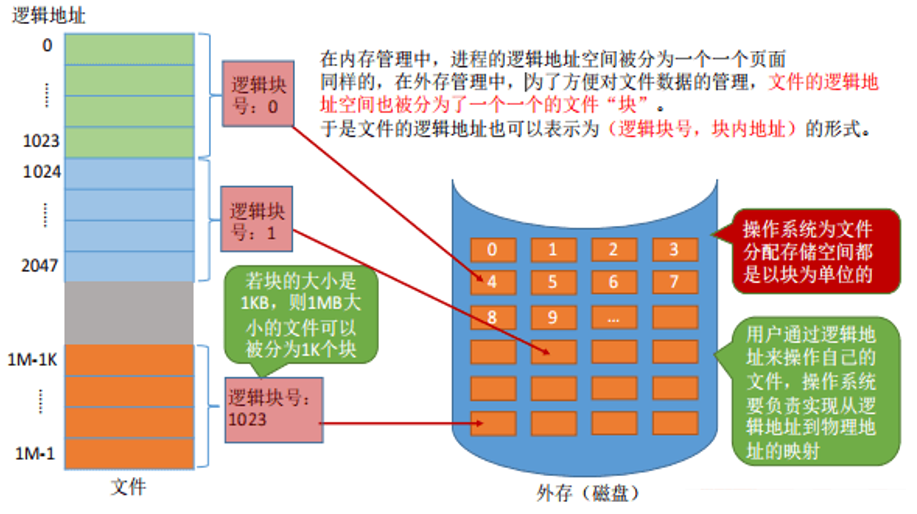
类似于内存分页,磁盘中的存储单元也会被分为一个个物理块。很多操作系统中,磁盘块的大小与内存块、页面的大小相同,例如内存块如果一个块大小是1K,那么磁盘块的大小也会为1K或者1K的倍数。为了方便对文件数据的管理,文件的逻辑地址空间也被分为了一个一个的文件“块”。
和内存地址类似,文件的逻辑地址也可以表示为(逻辑块号,块内地址)的形式。每个文件的逻辑块号从0开始。
接下来介绍物理块的分配方式,我们需要关注这几个问题:每种分配方式如何实现逻辑块号到物理块号的映射,根据一个逻辑块号读取一个物理块需要的IO次数是多少,当文件块数增加时(即文件的修改和追加内容)是否方便扩展文件。
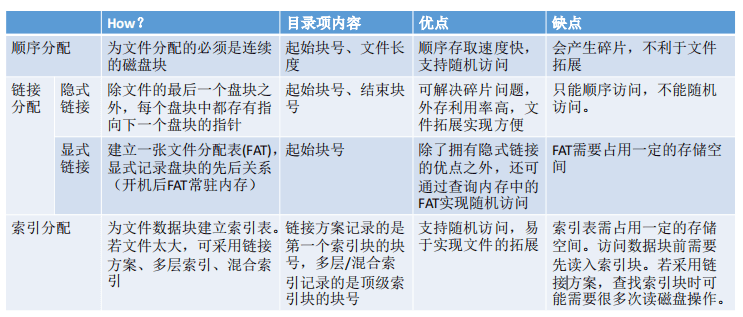
连续分配
连续分配方式要求每个文件在磁盘上占有一组连续的块。
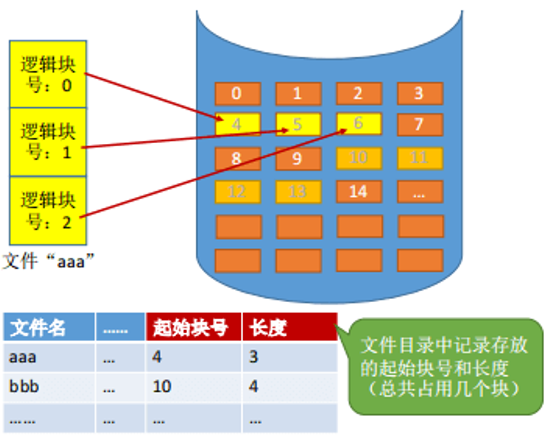
已知一个文件打开后,它的信息如文件名、起始块号和长度就载入到内存中了,根据文件标识符就能获取这些信息。
Q1:如何实现文件的逻辑块号到物 理块号的转变?
如果用户想读取逻辑块号i中的文件内容。那么 目标数据的 物理块号 = 起始物理块号 + 逻辑块号。
Q2:读取一个物理块需要的IO次数是多少?
连续分配就行数组一样支持随机访问第i号逻辑块,所以根据一个逻辑块号访问一个块的IO次数是1次。
连续分配的优点:
从磁盘的物理特性来说,读取某个磁盘块时,需要先移动磁头到这个磁盘块的开始位置。访问的两个磁盘块相隔越远,移动磁头所需时间就越长。因此连续分配的文件在顺序读取多个逻辑上连续块的情况下速度最快。
连续分配的缺点:
物理上连续分配的文件A占用了连续的三个块。若此时文件A要拓展多一个磁盘块。由于采用连续结构,
因此只能将文件A全部迁移到有4个连续空闲块的绿色区域,开销很大。如下图所示,文件A的从黄色的三个磁盘块全部拷贝到下方绿色的四个连续空闲磁盘块,拷贝需要消耗额外的时间。
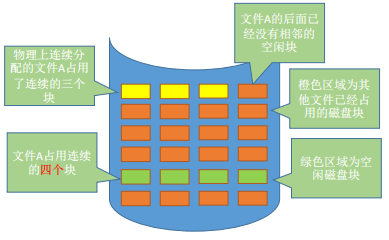
此外连续分配无法充分利用磁盘碎片,也容易产生磁盘碎片,因此磁盘利用率高。可以用紧凑技术(将已使用的磁盘空间集中在一边,将未使用的块集中在另一边,把小的空闲磁盘碎片连成一片大的空闲空间)来处理碎片,但是需要耗费很大的时间代价。
总结:
连续分配的优点:支持随机访问;连续分配的文件在顺序访问多个块时速度最快。
连续分配的缺点:不方便文件拓展;存储空间利用率低,容易产生磁盘碎片。
读取一个逻辑块的IO次数:1次。
链接分配之隐式链接
特点:
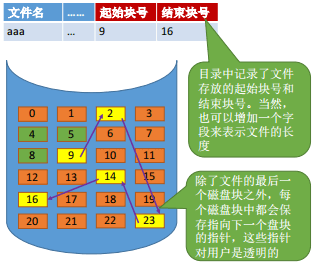
文件块按照链式存储,每个块离散的存储在磁盘中,且每个块会记录下一个块的指针。一个文件的索引节点中记录了文件存放的起始物理块号 和 结束物理块号。
PS:文件索引节点存储着文件除文件名之外的所有基本信息,如文件的起始物理地址、读写权限、创建/修改时间等。一个文件只对应有一个索引节点,一个目录保存着该目录下所有第一层文件的所有索引节点的地址。
Q1:如何实现文件的逻辑块号到物理块号的转变?
如果要读取 i
号逻辑块,要将起始的9号物理块(0号逻辑块)读入内存,由此知道1号逻辑块存放的物理块号2,然后读入2号物理块,再找到2号逻辑块的存放位置……以此类推直到找到
i 号逻辑块。
Q2:读取一个物理块需要的IO次数是多少?
读入i号逻辑块,总共需要 i+1 次磁盘 I/O。读取一个逻辑块的平均IO次数是 n/2。
Q3:扩展性如何?
若要为文件扩展新的磁盘块,可以在磁盘中随便找一个空闲磁盘块,挂到文件磁盘块链表的链尾,不会有碎片问题, 外存利用率高。
隐式链接分配的优点:很方便文件拓展;不会有碎片问题故而外存利用率高。
隐式链接分配的缺点:只支持顺序访问不支持随机访问;查找效率低,为O(n)复杂度;每个磁盘块要保存指向下一个盘块的指针也需要耗费少量的存储空间。
读取一个逻辑块的IO次数:平均 n/2 次,n是文件的总盘块数。
链接分配之显式链接
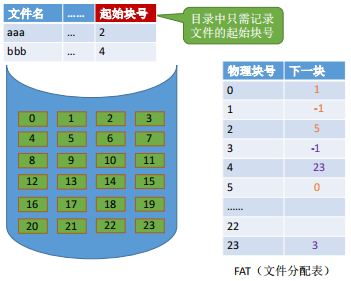
特点:
文件块按照链式存储,每个块离散存储,但不记录下一个块的指针。所有物理块的下一个块物理地址统一存储在一个文件分配表 FAT
中。文件索引节点记录文件存放的起始物理块号,但不记录结束物理块号。
一个磁盘仅设置一张FAT。开机时,将FAT读入内存,并常驻内存。FAT
的各个表项在物理上连续存储,且每一个表项长度相同,因此“物理块号”字段可以是隐含的,不占空间的。
Q1:如何实现文件的逻辑块号到物理块号的转变?

假设我们的目标逻辑块号是 3,已知逻辑块0的物理块号是2,则查询内存中的FAT[2] = 5(逻辑块号1),再找 FAT[5] = 0(逻辑块号2),再找
FAT[0] = 1(逻辑块号3)。这样我们就得知逻辑块号为3的物理块号是1。
FAT表本质是一个数组,因此访问 FAT[k]的复杂度是O(1)。
Q2:读取一个物理块需要的IO次数是多少?
逻辑块号转换成物理块号的过程不需要读磁盘操作。因此IO次数为1,就是直接读取目标物理块的那次IO操作。所以显式链接支持随机访问。
Q3:扩展性如何?
不会产生外部碎片,也可以很方便地对文件进行拓 展。
显式链接分配的优点:很方便文件拓展;不会有碎片问题,外存利用率高;支持随机访问。相比于隐式链接来说,地址转换时不需要访问磁盘,因此文件的访问效率更高。
显式链接分配的缺点:文件分配表的需要占用一定的存储空间(1T的磁盘,FAT表可能占几十到上百M,而且几百兆是要直接载入内存的,这点很糟糕)。
索引分配
索引分配允许文件离散地分配在各个磁盘块中,系统会为每个文件建立一张索引表,索引表中记录了文件的各个逻辑块对应的物理块。一个文件中的索引表本身占用的磁盘块称为索引块。文件数据占用的磁盘块称为数据块。
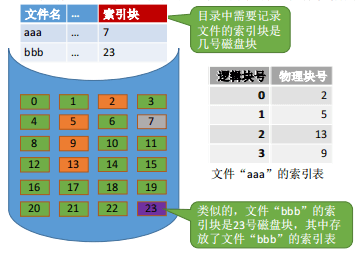
假设某个新创建的文件“aaa”的数据依次存放在磁盘块 2 -> 5 -> 13 -> 9 。7号磁盘块作为“aaa”的索引块, 索引块中保存了索引表的内容。
可以用固定的长度表示磁盘块号(如:假设磁盘总容量为1TB=2^40B,磁盘块大小为1KB,则共有 2^30个磁盘块,则可用 4B
表示磁盘块号),索引表中的“逻辑块号可以是隐含的。
Q1:如何实现文件的逻辑块号到物 理块号的转变?
用户给出要访问的逻辑块号 i。
首先根据索引块的起始物理块号将整个索引表从外存读入内存(索引表可能占了多个索引块的大小),查找索引表[i] 得到 i 号 逻辑块的物理块号。
索引分配方式可以支持随机访问。
Q2: 扩展性如何?
文件拓展也很容易实现,只需要给文件分配一个空闲块,并增加一个索引表项即可。
但是索引表本身需要占用一定的存储空间。
Q3:如果一个文件的大小超过了256 块,那么一个磁盘块是装不下文件的整张索引表的,如何解决这个问题?有3种解决方法:①链接方案;②多层索引;③混合索引
链接方案 :如果索引表太大,一个索引块装不下,那么可以将多个索引块链接起来存放。
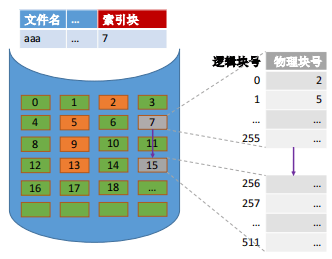
假设磁盘块大小为1KB,一个索引表项占4B,则一个磁盘块只能存放256 个索引项。
若一个文件大小为 256*256KB = 65,536 KB = 64MB
那么该文件共有 256*256 个数据块,也就需要 256 个索引块来存储索引表,这些索引块用链表连起来。
若想要访问文件的最后一个逻辑块, 就必须找到最后一个索引块(第256 个索引块),而各个索引块之间是用指针链接起来的,因此必须先顺序地从磁盘读入前 256
个索引块到内存中。一共要发生257次IO操作。该索引方式的缺点是读取一个逻辑块会发生太多次磁盘IO。
多层索引
:将索引表分层,使第一层索引块指向第二层的索引块。还可根据再建立第三层、第四层索引块。顶层索引表只占一个索引块,非底层的索引表表项记录指向的下一层索引表的开始地址,底层的索引表表项指向数据块地址。
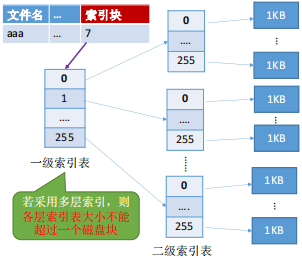
采用 K 层索引结构,则访问一个数据块只需要 K + 1 次 读磁盘操作,相比于链接方案而言文件数据寻址节省了很多次磁盘IO。
该索引方式的缺点是一个只占几个数据块的小文件,由于索引表的多层级,读取一个逻辑块也要发生多次磁盘IO。
混合索引 :多种索引分配方式的结合。例如,一个文件的顶级索引表中,既包含直接地址索引(直接
指向数据块),又包含一级间接索引(指向单层索引表)、还包含两级间接索引(指向两层索引表) 。
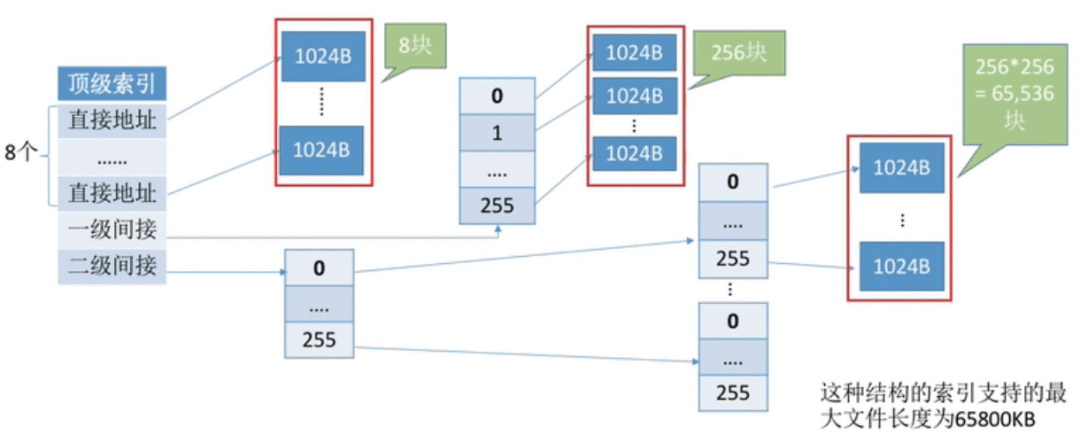
如上图,假设顶级索引表没有读入内存。
访问0~7号逻辑块中的某一块,需要2次磁盘IO。
访问8~263号逻辑块中的某一块,需要3次磁盘IO。
访问264~65799号逻辑块中的某一块,需要4次磁盘IO。
对于小文件,只需要较少的磁盘IO即可读到目标数据块。
文件物理结构和分配方式小结
02 磁盘结构
一个磁盘的盘面被分为一圈圈的 磁道,一个磁道又被分为一个个扇区,一条指定磁道上的一个扇区就是一个** 磁盘块
** 。 一个盘面的磁道大概有几千到几万条。
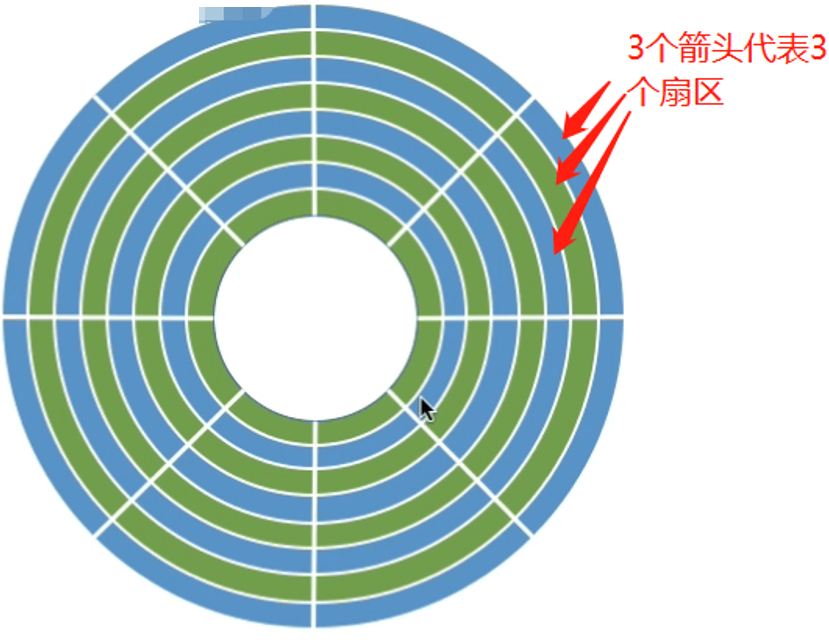
最中间的白色同心圆放着一个马达用来转动盘面,另外还有可移动的磁头。磁头只能在同一扇区内的不同磁道上移动,只有马达转动盘面才可以让磁头到达另一个扇区的磁道。让目标扇区从磁头下面划过,才能完成对扇区的读/写操作。
如下图所示,一个磁盘包含多个盘面,通过一个盘臂组装在一起。盘臂长着多个 磁头 ,每个盘面对应一个磁头。所有的磁头都 是连在同一个
磁臂上的,因此所有磁头只能“共进退”。但磁盘只读取/写入某一个激活了的磁头所划过的地方。
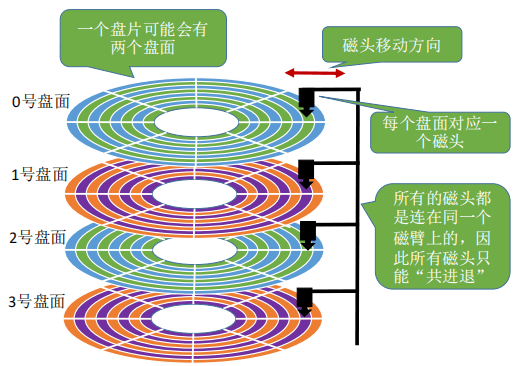
所有盘面的相同磁道(如下图黄色的磁道)组成 柱面 。
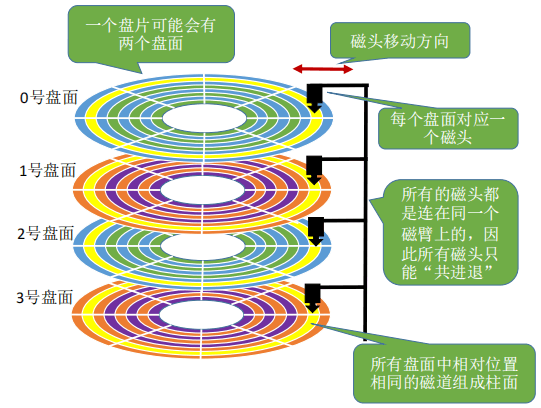
一个物理块号实际上由是一个(柱面号,盘面号,扇区号)的三元组信息定义的。块号可以转换成(柱面号,盘面号,扇区号) 的地址形式。
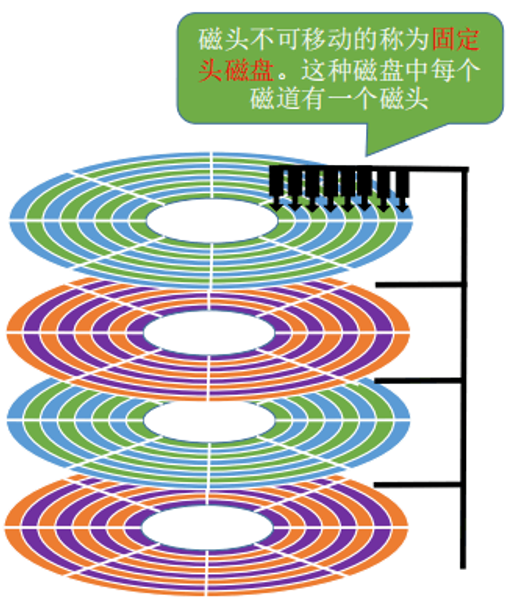
还有一种固定头磁盘,它的每个盘面的每个磁道都有一个磁头,磁头无法移动:
03 磁盘调度算法
一次磁盘读写操作所需的时间 = 寻道时间 + 延迟时间 + 传输时间
寻道时间(TS):在读/写数据前,将磁头移动到指定磁道所花的时间。它又包括:
①启动磁头臂是需要时间的。假设耗时为 s;
②移动磁头也是需要时间的。假设磁头匀速移动,每跨越一 个磁道耗时为 m,总共需要跨越 n 条磁道。
则:
寻道时间 TS = s + m*n
延迟时间(TR):通过旋转磁盘,使磁头定位到目标扇区所需要的时间。
设磁盘转速为 r (单位:转/秒,或 转/分),则平均所需的延迟时间是转二分之一圈的时间 TR = (1/2)*(1/r) = 1/2r
传输时间(Tt):磁头从磁盘读出/写入数据的开始位置划到结束位置所经历的时间,假设磁盘转速为 r,此次读/写的字节数为 b,每个磁道上的字节数为
N。则:传输时间Tt = (1/r) * (b/N) = b/(rN)
延迟时间和传输时间都与磁盘转速有关,且为线性相关。而转速是硬件的固有属性,
因此操作系统也无法优化延迟时间和传输时间,只能优化寻道时间,也就是说它只能优化磁头跨越磁道的条数。
下面介绍具体的磁盘调度算法,假设磁头的初始位置是100号磁道,有多个进程先后陆续地请求访问 55、58、39、18、90、160、 150、38、184
号磁道。
先来先服务(FCFS)
根据进程请求访问磁盘的先后顺序进行调度。按照 FCFS 的规则,按照请求到达的顺序,磁头需要依次移动到 55、58、39、18、90、160、150、
38、184 号磁道。
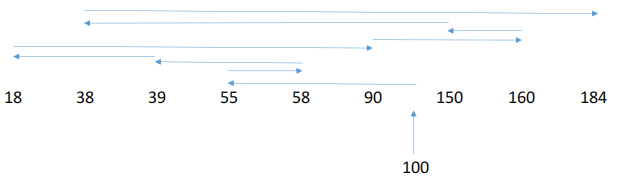
磁头总共移动了 45+3+19+21+72+70+10+112+146 = 498 个磁道。
响应一个请求平均需要移动 498/9 = 55.3 个磁道(平均寻找长度)。
优点:公平;如果请求访问的磁道比较集中的话,算法性能还算过的去。
缺点:如果有大量进程竞争使用磁盘,请求访问的磁道很分散,则FCFS在性能上很差,寻道时间长。
最短寻找时间优先(SSTF)
SSTF
算法会优先处理的磁道是与当前磁头最近的磁道。可以保证每次的寻道时间最短,但是并不能保证总的寻道时间最短。其本质是贪心算法的思想,只是选择眼前最优,但是总体未必最优。
假设磁头的初始位置是100号磁道,有多个进程先后陆续地请求访问 55、58、39、18、90、160、 150、38、184 号磁道。

磁头总共移动了 (100-18) + (184-18) = 248 个磁道。
响应一个请求平均需要移动 248/9 = 27.5 个磁道(平均寻找长度)。
优点:性能较好,平均寻道时间短。
缺点:可能产生“饥饿”,新来的较近的磁道请求插队导致之前那些较远的磁道请求无法得到处理。
扫描算法(SCAN)
SSTF 算法会产生饥饿的原因在于:磁头有可能在一个小区域内来回来去地移动。
为了防止这个问题, 规定只有磁头移动到最外侧磁道的时候才能往内移动,移动到最内侧磁道的时候才能往外移动。这就是扫描算(SCAN)的思想,也叫电梯算法。

磁头总共移动了 (200-100) + (200-18) = 282 个磁道。
响应一个请求平均需要移动 282/9 = 31.3 个磁道(平均寻找长度)。
优点:性能较好,平均寻道时间较短,不会产生饥饿现象
缺点:①只有到达最边上的磁道时才能改变磁头移动方向,因此会造成多余的磁道跨越。
②SCAN算法对于各个位置磁道的响应频率不平均,两边的磁道响应快,中间磁道慢。
为了解决这两个缺点,提出了C-LOOK调度算法。
C-LOOK 调度算法
该算法是 边移动边观察算法(LOOK算法 )和循环扫描算法(C-SCAN算法) 的结合。
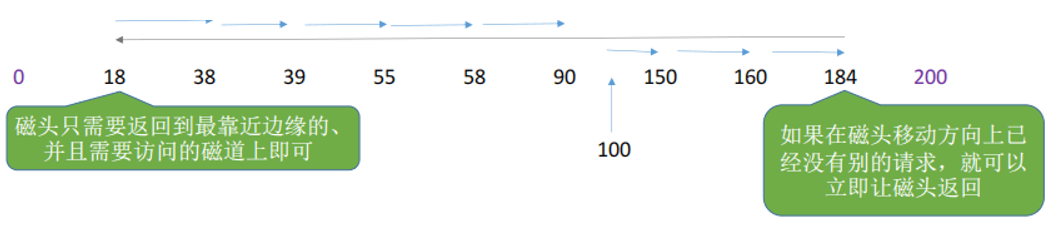
如果在磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向,这就是LOOK算法的思想。

只有磁头从盘片的圆心磁道到边缘磁道方向移动时才处理磁道访问请求,而从边缘磁道返回到圆心磁道的过程直接快速移动不处理任何请求。这就是C-SCAN算法的思想。

C-LOOK算法思想则是如果磁头移动的方向上已经没有
磁道访问请求了,就可以立即让磁头返回,返回的过程不处理请求,并且磁头只需要返回到有磁道访问请求的位置即可。
减少延迟时间的方法
首先我们需要知道扇区是有编号的,如下图所示:
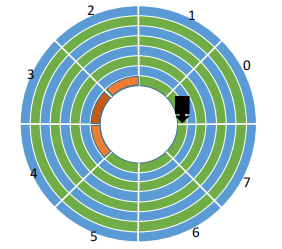
考虑一种场景,假设要连续读取橙色区域的编号为 2、3、4的扇区。
磁头读取一磁盘块的内容后,需要一小段时间处理,无法马上读取下一个扇区的内容,而盘片又在不停地旋转,也就是说相邻扇区的内容无法立刻读入。
因此,磁头读完2号扇区后无法连续不断地读入3号扇区。必须等盘片继续旋转一圈, 转到3号扇区再次划过磁头,才能完成扇区读入。
如此一来需要转2圈才能成功读取2、3、4扇区的块。
结论是:磁头读入一个扇区数据后需要一小段时间处理, 如果逻辑上相邻的扇区在物理上也相邻,则读入几个连 续的逻辑扇区,可能需要很长的“延迟时间”。
为了解决这个问题,可以对扇区进行 交替编号 ,让逻辑上相邻的扇区在物理上有一定的间隔,使读取连续的逻辑扇区所需要的延迟时间更小。
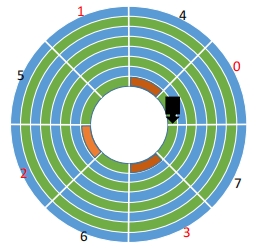
此外不同盘面的扇区编号需要交错,也就是0号盘面的1号扇区的正下方不能对着1号盘面的1号扇区。这也是为了让逻辑上相邻的扇区在物理上不能相邻。
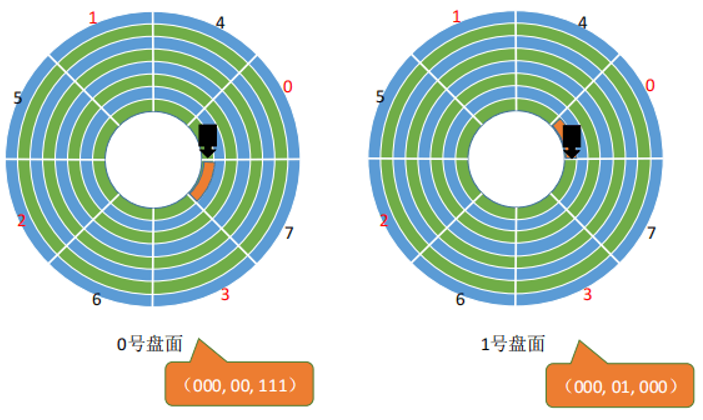
如下方所示用(x,y,z)表示柱面x、盘面y和扇区z,如果需要读取从(0, 0, 7) 到(0, 1,
0)这2个相邻盘块,这两个盘块位于两个盘面上,假如刚读完0号盘面的7号扇区,接着磁头就刚好指到了1号盘面的0号扇区,但由于处理数据需要时延,所以无法马上读取这第二个盘块。最终还是需要转多1圈才能读完这两个块。
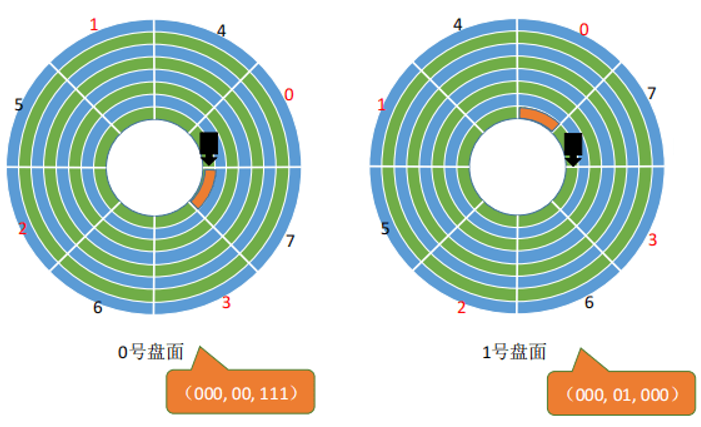
采用不同盘面的扇区交错编号可以避免这个问题。
04 顺序IO和随机IO
顺序IO是指读写的多个块在物理上是连续的,具体的物理表现为要读写的多个块在磁盘的同一磁道上或者相邻磁道的相邻扇区,磁头无需多次寻道(表现为磁头不用移动或只用移动一丢丢)就能读写这些块。
随机IO是指要读写的多个块在物理上是离散存储的,具体的物理表现为要读写的多个块在磁盘的多个不同的磁道上,磁头需要多次寻道才能读取他们。
我们知道磁头寻道是磁盘操作成本最高的部分。因此如果操作系统某个时刻瞬间发出的n次磁盘IO操作是顺序IO,它会很快的完成。如果随机IO,由于需要寻道,因此会比顺序IO慢很多。
所以同样是n次IO,多次顺序IO比多次随机IO要快很多。